1. 假设检验是什么
- 假设检验是一种 根据样本数据来判断某个关于总体的信念是否合理 的方法。
- 我们设定两个互斥的假设:
- 零假设 :基线假设,通常认为“没有变化”或“没有效果”。
- 备择假设 :我们真正感兴趣、想要验证的假设。
2. 例子:垃圾邮件检测
- 问题:一封邮件是 Ham(正常邮件) 还是 Spam(垃圾邮件)?
- 设计假设:
- : 邮件是正常邮件(Ham)。
- : 邮件是垃圾邮件(Spam)。
为什么这样设定?
因为 误删正常邮件比放进垃圾邮件更严重,所以默认认为邮件是 Ham(保守做法)。
3. 假设的特点
- 互斥性:不能同时为真。
- 邮件不可能既是 Ham 又是 Spam。
- 真/假判断:必须是能被数据支持或否定的明确命题。
4. 如何基于证据做判断
-
如果证据强烈反对 :
→ 拒绝零假设,接受 。
(例:邮件包含 “earn extra cash”, “apply now”等关键词 → 判定为 Spam) -
如果证据不足以反对 :
→ 不能拒绝零假设。
注意!这并不等于证明 为真,只是说明数据不够让我们接受 。
如果判断出错
1. 为什么会出错?
在假设检验中,我们只从样本里获得部分信息,无法直接知道总体的“真相”。
因此,即使设计了检验,也可能做出错误的决定。错误主要有两类:
2. 错误的两种类型
| 实际情况 / 决策结果 | 拒绝 | 不拒绝 |
|---|---|---|
| 为真 | I 型错误(Type I Error, α) 错误地拒绝了正确的 又称 False Positive | 正确决定 |
| 为真 | 正确决定 做出这个决定的概率为Power of a Test = 1 - β | II 型错误(Type II Error, β) 错误地接受了错误的 又称 False Negative |
Type I Error 比 Type II Error 更严重。
4. 显著性水平(Significance Level)
- 显著性水平 :能容忍的最大 I 型错误概率。
- 常见取值: 或 。
- 解释:如果 ,意味着平均有 5% 的正常邮件会被错判为垃圾邮件。
5. Type I 与 Type II 错误的权衡
- 降低 (减少 I 型错误) → 往往会增加 II 型错误。
- 增加样本量 → 可以同时减少两类错误。
- 实际应用中,需要根据问题的重要性决定优先避免哪种错误。
判断H_0的分布是否常见/应如何对待:
- 看 p 值 (p-value)
- Critical Value
如果只看对于H_1的证明,根据 备择假设 的方向,检验可分为三类:
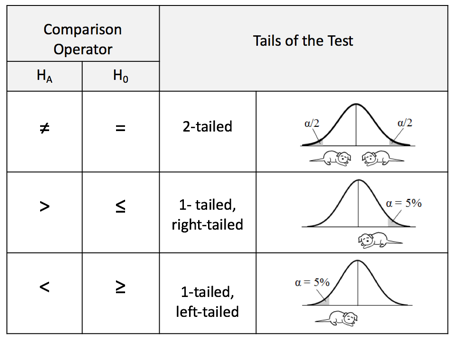
单尾检验:
- 右尾检验 (Right-Tailed Test)
- 情景:想证明总体均值 增加。
- 假设设置:
- 判定规则:如果样本均值 显著大于 ,拒绝 。
- 错误类型:
- Type I:实际 ,却判定 。
- Type II:实际 ,却没有拒绝 。
- 左尾检验 (Left-Tailed Test)
- 情景:想证明总体均值 减少。
- 假设设置:
- 判定规则:如果样本均值 显著小于 ,拒绝 。
- 错误类型:
- Type I:实际 ,却判定 。
- Type II:实际 ,却没有拒绝 。
双尾检验 (Two-Tailed Test)
- 情景:想证明总体均值 发生了变化(可能变大也可能变小)。
- 假设设置:
- 判定规则:如果样本均值 与 的差异 过大(无论正负),拒绝 。
- 通常用 来衡量。
- 错误类型:
- Type I:实际 ,却判定 。
- Type II:实际 ,却没有拒绝 。
t-Tests:现实中通常 不知道总体标准差 ,用 样本标准差 代替 ,得到t-Distribution