1. 研究背景与问题
- 为什么要做 inverse rendering? 为了从(单张或多张,本文是单张)图片推测Geometry、Material、Illumination
- 室内场景的特殊挑战(复杂光照、反射、材质多样)。 含有Global Illumination Effects,ill-posed problem
- 传统方法 & 深度学习方法的不足。
- Physics-based Optimization:依赖强人工Prior和Regularization Term,方法假设过于简化,导致反演精度和重渲效果较差。
- 深度学习方法:依赖数据集的 真实性与质量 + 网络结构设计。渲染层不够物理化,尤其处理高光、镜面反射差。鲁棒性不足。
2. 核心贡献
- 方法层面的新意。
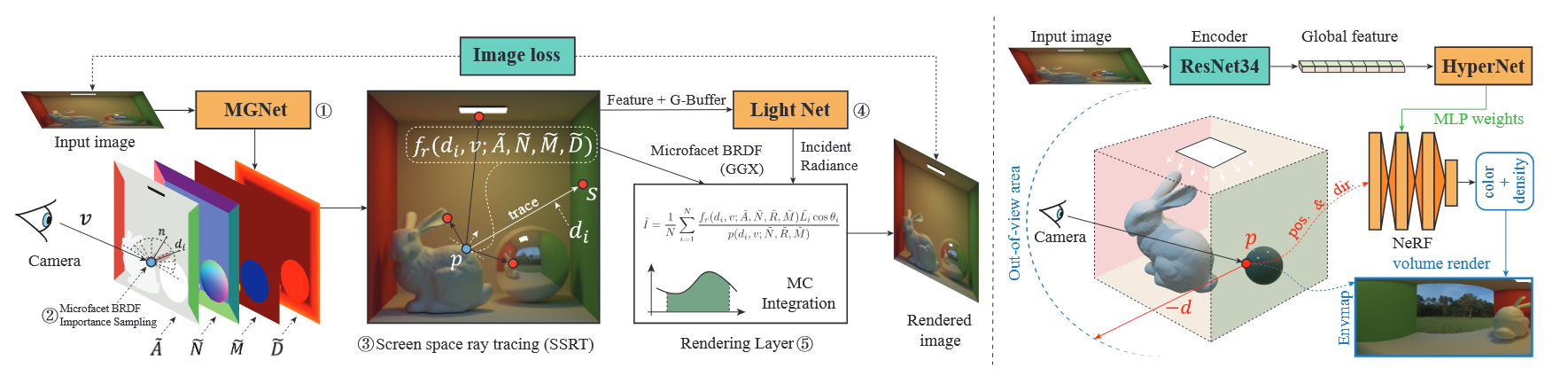 图左(新型 MC 可微渲染层:基于重要性采样 + SSRT)和图右(不确定性感知视域外光照网络:HyperNetwork+NeRF)
图左(新型 MC 可微渲染层:基于重要性采样 + SSRT)和图右(不确定性感知视域外光照网络:HyperNetwork+NeRF) - 数据集的贡献。 InteriorVerse 数据集:约 4000 个复杂室内场景,用 GGX 物理材质渲染。
- 整体框架的优势。 提出端到端学习框架,可从单张图恢复反照率、法向、深度、粗糙度、金属性。
3. 相关工作对比
Inverse Rendering of Indoor Scenes
以往方法的局限
-
几何 (Geometry)
-
研究较多,主要是 深度估计 和 法线预测。
-
代表性工作:
-
Eigen & Fergus 2015
-
Liu et al. 2019
-
-
-
材质 (Material)
-
多数方法只能做到:
-
估计漫反射反照率 (Diffuse Albedo)
-
[Barron & Malik 2013]
-
[Karsch et al. 2014]
-
[Li & Snavely 2018]
-
-
或者分类材质类别 (Material Category)
- [Bell et al. 2015]
-
-
缺乏对复杂 BRDF 的全面恢复。
-
-
光照 (Lighting)
-
早期方法:预测全局环境光照 (Global Illumination Map)
- [Gardner et al. 2017, 2019]
-
最新方法:开始估计空间可变的光照 (Spatially-varying Lighting)
-
[Garon et al. 2019]
-
[Li et al. 2020]
-
[Song & Funkhouser 2019]
-
-
从框架整体来看,计算像素颜色的效果更好,具体原因是各个框架都变了。
以往的不足:
- Physics-based Optimization 规则不完美
- 深度学习方法输入不完美(Li et al., 2020)
- ill-posed Problem
- 数据集不够真实
- 渲染时使用的 environment map 忽略局部的高强度反射
本文改善:
- 两个大方法和一个更真实的数据集
Lighting Estimation & Relighting
Lighting Estimation
-
定义:逆渲染中的子任务 → 从图像中推断场景的光照分布。
-
传统方法
-
假设整个场景共享 单一环境光图 (environment map)。
-
代表:
-
Gardner et al. 2017
-
Munkberg et al. 2022
-
Sengupta et al. 2019
-
-
缺陷:忽略了室内场景的空间变化(不同位置光照不同)。
-
-
近期进展:空间可变光照 (Spatially-varying Lighting)
-
表示方式:
-
环境贴图 (Environment Maps)
-
像素级球面 lobes(Spherical Harmonics / Gaussians)[Li et al. 2020]
-
三维体素网格 (3D Voxel Grids) [Wang et al. 2021b]
-
-
Relighting
-
定义:修改场景中的光照条件以生成新图像。
-
代表方法:
-
Griffiths et al. 2022 → 使用 屏幕空间方法 检测遮挡并生成阴影,用于室外图像重光照。
-
Li et al. 2022 → 提出新 pipeline,可修改室内场景的光照条件。
-
从光照估计来看,光源更真实,因为增加了视野外的计算和对重要光源的加权
以往的不足:
- 算光照
- 单一环境图(如 Gardner’17):所有像素点共用一种计算光照的方式
- 球面高斯(Li’20):不同像素点计算光照的系数不同,但仍变化缓慢/低频
- 3D 光照体素(Wang’21b):3D voxel grid 存储光照信息,但计算量大
- Relighting
- 屏幕空间方法(Griffiths’22)、改灯管线(Li’22):无法预测相机视角外的光,不能实现局部高清修改
- 用 LDR 作为数据集
本文改善:
- 补足画面外光照,高频,通过从 沿 方向找到的点来计算光强,更物理
Neural Scene Representations
-
Voxels (体素网格)
-
[Sun 2021; Yu 2021a]
-
把 3D 空间离散成小立方体(体素),每个体素存储颜色/密度信息。
-
缺点:分辨率受内存限制。
-
-
Hashgrids (哈希网格编码)
-
[Müller 2022]
-
使用多尺度哈希表存储特征,比体素更高效。
-
NeRF 加速常用方法(Instant-NGP)。
-
-
Point Clouds (点云)
-
[Aliev 2020]
-
用稀疏的点表示场景,点上附带颜色/法线/特征信息。
-
渲染速度快,但连续性较差。
-
-
Neural Implicit Functions (神经隐式函数)
-
[Mildenhall 2020; Wang 2021a; Yariv 2020, 2021]
-
用 MLP 隐式建模:输入 3D 坐标 ,输出颜色和密度。
-
代表作:NeRF (Neural Radiance Fields)。
-
本文用 HyperNetwork + NeRF 来做光照补全而不是几何重建,计算量小
Differentiable Rendering
背景
-
可微分渲染 (Differentiable Rendering):
在渲染过程中保留梯度信息,使得光照、材质、几何参数可以通过反向传播学习。 -
在逆渲染 (Inverse Rendering) 中,核心作用是让网络可以“感知”物理光传输,从而优化参数。
现有研究
-
通用物理可微分渲染器
-
[Li et al. 2018a; Nimier-David et al. 2019]
-
面向通用场景,物理精确,可以处理复杂全局光照。
-
缺点:计算开销极大,速度慢。
-
-
理论研究
-
[Zhang et al. 2020; Zeltner et al. 2021]
-
提出可微光传输与蒙特卡洛采样的严格理论基础。
-
-
专用型方法(任务定制化)
-
纹理优化 [Nimier-David et al. 2021]
-
Split-sum 光照 & 网格提取 [Munkberg et al. 2022]
-
针对特定问题优化性能,但缺乏通用性。
-
本文的创新
-
设计了一个基于 Monte Carlo 的网络内可微分渲染层:
-
内嵌在模型里,而不是独立渲染器。
-
使用 重要性采样 + 屏幕空间光线追踪 (SSRT)。
-
目标:更真实地恢复室内场景的外观,尤其是高光和反射。
-
对比传统方法 → 保持物理性,同时减少计算开销。
-
仔细算物理的话速度慢,只算近似的话又只有低频信息。MC 可微渲染层算是折中
方法细节
Material and Geometry Network (MGNet)
输入
-
单张高动态范围 (HDR) 图像
-
来源:合成数据集可直接获取
-
对于真实照片:需先进行 逆伽马校正 (inverse gamma correction)
-
核心结构
-
DenseNet121 编码器
- 提取场景的深层特征(涵盖材质和几何信息)
-
四个独立解码器 → 输出四类结果:
-
Albedo (A):反照率/基色
-
Material (M):包括
-
粗糙度 (Roughness, R)
-
金属度 (Metallic, Mt)
-
-
Normal (N):表面法线
-
Depth (D):深度图
-
训练技巧
-
解码阶段:
-
上采样 (Upsampling)
-
跳跃连接 (Skip Links)
-
目的:保留多层级的细节信息,提高预测的精细度
-
Lighting Network (LightNet)
目标
预测任意点 p 在方向 d 上的入射光强度 。
1. 坐标系设置
-
固定为 输入图像的相机坐标系。
-
点 表示场景中的像素位置,方向 表示入射光方向。
2. 特征提取
-
输入图像 → ResNet34 编码器 E → 特征图 。
-
任意三维点 可以投影到图像坐标 ,从而取到 作为局部特征。
3. 核心思路(改进点)
-
不是直接用点 的特征,而是:
-
从点 沿着 方向做光线追踪 → 得到交点 。
-
取 对应的特征向量 。
-
理解: 像是“虚拟点光源”的位置,携带了入射光的真实来源信息。
-
4. 最终光照预测
把这些信息输入 MLP 解码器 :
其中:
-
= 位置编码(NeRF 常用,用来表达方向的高频信息)。
-
= G-Buffer 信息(包括漫反射 、镜面反射 、法线 、粗糙度 )。
5. Screen-Space Ray Tracing (SSRT) 实现
-
输入:深度图 、起点 、方向 。
-
方法:逐像素 ray marching。
-
每一步计算当前光线深度 vs. 场景深度。
-
如果光线深度 大于 场景深度 → 相交,记录交点。
-
否则继续前进,直到出屏幕边界。
-
Uncertainty-Aware Out-of-View Lighting Network
1. 局限性(为什么需要它)
- SSRT 的问题:屏幕空间光线追踪只能在图像视野范围内工作。
- 光线延伸到 视野之外,可能:
- 找不到交点
- 产生 假交点 (false positive)
- 结果:光照估计错误,尤其在复杂室内场景中。
2. 解决方案(核心思路)
- 设计一个 视野外光照网络,灵感来自 NeRF:
- NeRF 用 MLP 表示体积辐射场,通过体积渲染得到光照。
- 但原版 NeRF 需为每个场景单独训练 MLP,效率低。
- 本文采用 HyperNetwork:
- 输入图像 → 提取全局特征 (ResNet34 编码器)。
- 将 输入 HyperNetwork ,输出该场景的 NeRF MLP 权重 。
- 一张图像即可生成一个“专属 NeRF”,快速预测视野外光照。
3. 推理过程(光照估计公式)
-
在光线 上采样 个点:
-
输入 NeRF MLP:
- :密度
- :RGB 颜色
- :位置编码
-
体积渲染得到光照:
其中
4. 与 SSRT 的融合(不确定性感知)
-
问题:SSRT 可能产生“假交点”。
-
判别方法:比较光线深度与表面深度差值 。
-
不确定性权重:
-
融合公式:
-
当 小(可信) → 以 SSRT 为主
-
当 大(不可信) → 以 NeRF 为主
Differentiable Monte Carlo Rendering Layer
1. 背景
- Li et al. (2020) 方法:
- 将入射半球 离散化,用固定方向近似积分。
- 缺点:对 镜面 / 高光反射 容易采样不到 → 出现伪影。
- 类比:就像只在几个固定角度“偷看”光线,可能漏掉重要的反射方向。
2. 本文改进
采用 可微分蒙特卡洛 (MC) 光线追踪 + BRDF 重要性采样:
-
BRDF 重要性采样
- 根据视角 、法线 、粗糙度 、金属度 ,生成 个采样方向 。
- 采样分布与 BRDF 匹配,更可能捕捉到镜面反射方向。
-
屏幕空间光线追踪 (SSRT)
- 沿着每个 追踪,找到光源点 。
- 利用 LightNet 预测该方向的入射光 。
-
积分重建图像
- :BRDF 评价值
- :重要性采样的概率密度函数 (PDF)
- :入射光与法线夹角
3. 效果对比
- Li et al. (2020):
- 高频反射方向经常遗漏 → 高光区域出现 条纹伪影。
- 本文方法 (MC + Importance Sampling):
- 能恢复出 逼真的镜面反射,效果更贴近 Ground Truth。
5. 数据集 InteriorVerse
-
与现有数据集对比。
-
GGX BRDF 的物理真实感。
-
场景复杂度与多样性。
6. 实验与结果
训练策略
采用 渐进式训练 (Progressive Training),按照网络组件之间的数据依赖顺序进行:
-
阶段一:训练 Material-Geometry 模块 (MGNet)
- 目标:正确预测
- Albedo(反照率)
- Normal(法线)
- Roughness(粗糙度)
- Metallic(金属度)
- Depth(深度)
- 原因:
- 这些属性是 光照网络 (LightNet) 的输入条件。
- 例如:
- SSRT 依赖深度信息才能进行光线追踪。
- MLP 解码器 需要 G-Buffers(几何+材质特征)作为输入。
- 目标:正确预测
-
阶段二:训练 Lighting 模块 (LightNet)
- 在已有的材质和几何预测基础上,利用 重渲染损失 () 进一步优化光照预测。
Material-Geometry:几何与材质重建
- 直接监督 (Direct Supervision)
- 计算网络预测值与真值之间的误差。
- 保证法线、深度、粗糙度、金属度、反照率等基本属性正确。
损失函数设计
MGNet 的训练目标函数由 材质损失 + 几何损失 组成:
其中:
- :反照率(Albedo)损失
- :材质损失(包含 粗糙度 + 金属度 )
- :法线损失
- :深度损失
- :加权系数
感知损失 (Perceptual Loss)
- 在 albedo / normal / material 项中引入 感知损失 [Johnson et al. 2016]。
- 作用:
- 让网络不仅对数值误差敏感,还能关注 语义边界(如墙角、家具边缘)。
- 避免预测结果过于平滑,提高纹理和几何边界的细节保真度。
LightNet:光照估计
- 目标:恢复逼真的场景外观。
- 做法:
- 在训练中加入 可微渲染层 (Differentiable Rendering Layer)。
- 使用预测的材质、几何、光照重新渲染图像 。
- 通过 图像损失 (Image Loss) 约束 。
损失函数设计
LightNet 的训练目标由 直接光照监督损失 + 重渲染损失 组成:
-
- HDR 光照监督损失 (Mildenhall et al. 2021)
- 直接约束网络预测光照与真值光照的一致性。
-
- L2 损失
- 在预测材质 + 几何 + 光照的基础上重新渲染图像 ,
约束 与输入图像 尽量接近。
关键改进
- 引入重渲染损失:
- 强制网络学习 正确的像素亮度分布。
- 避免预测光照过于模糊或出现斑点伪影。
- 尤其在 高光/镜面表面 上提升显著。
6.1 Experiment Settings
1. 训练数据
- 主数据集:InteriorVerse(本文新提出的高保真室内场景数据集,详见 Sec.3)。
- 输入:(图像)
- 监督属性:
- = Albedo(反照率)
- = Normal(法线)
- = Depth(深度)
- = Roughness(粗糙度)
- = Metallic(金属度)
- = Lighting(空间可变光照)
- 真实数据微调 (Fine-tuning):
- IIW dataset [Bell et al. 2014] → 用于 Albedo 预测
- NYUv2 dataset [Silberman et al. 2012] → 用于 Depth & Normal 预测
2. 对比基线
-
Li et al. (2020)
- 当前室内场景逆渲染的 SOTA 框架。
- 为了公平对比,作者在 InteriorVerse 上重新微调了该方法 → 性能有明显提升 (见 Fig.5)。
-
Lighthouse [Srinivasan et al. 2020]
- 另一种 SOTA 光照估计方法。
- 输入要求:立体图像对 (stereo pair),而非单张图像。
- 作为光照预测的对比基线。
4. 与以往方法的不同
-
Li et al. (2020):渲染层采用离散化近似 → 对高光/镜面反射不稳定。
-
本文方法:
- 渲染层采用 物理真实的蒙特卡洛采样 (Monte Carlo Sampling)。
- 融合 屏幕空间光线追踪 (SSRT) + GGX 重要性采样。
- 显式正则化了物理参数空间,使训练更加鲁棒。
-
合成数据集对比。
-
真实数据集评测 (IIW, NYUv2)。
-
应用场景:
-
Multiple Complex Object Insertion
-
Material Editing
-
Holistic Inverse Rendering
-
7. 总结与未来方向
1. 结论 (Conclusion)
- 提出了一个 基于学习的逆渲染方法,专门用于复杂室内场景。
- 核心贡献:
- 能够处理 空间可变光照。
- 借助 可微分蒙特卡洛渲染层,成功恢复了真实的镜面反射。
- 支持 高保真场景编辑:如虚拟物体插入、材质修改等。
- 发布了一个全新的 大规模室内数据集 InteriorVerse,细节和真实性均优于现有替代方案。
2. 局限性 (Limitations)
-
视野外光照网络 (Out-of-View Lighting Network)
- 由于网络容量有限,无法预测高频细节。
-
蒙特卡洛采样 (Monte Carlo Sampling)
- 可能导致重渲染结果带噪声。
- 增加采样数量虽能缓解,但会显著提升计算开销。
-
光源发射 (Light Source Emission)
- 当前方法尚不支持显式处理光源发射。
- 计划作为未来工作拓展。