哈希表(hash table),又称散列表,它通过建立键 key 与值 value 之间的映射,实现高效的元素查询。具体而言,我们向哈希表中输入一个键 key ,则可以在 时间内获取对应的值 value 。
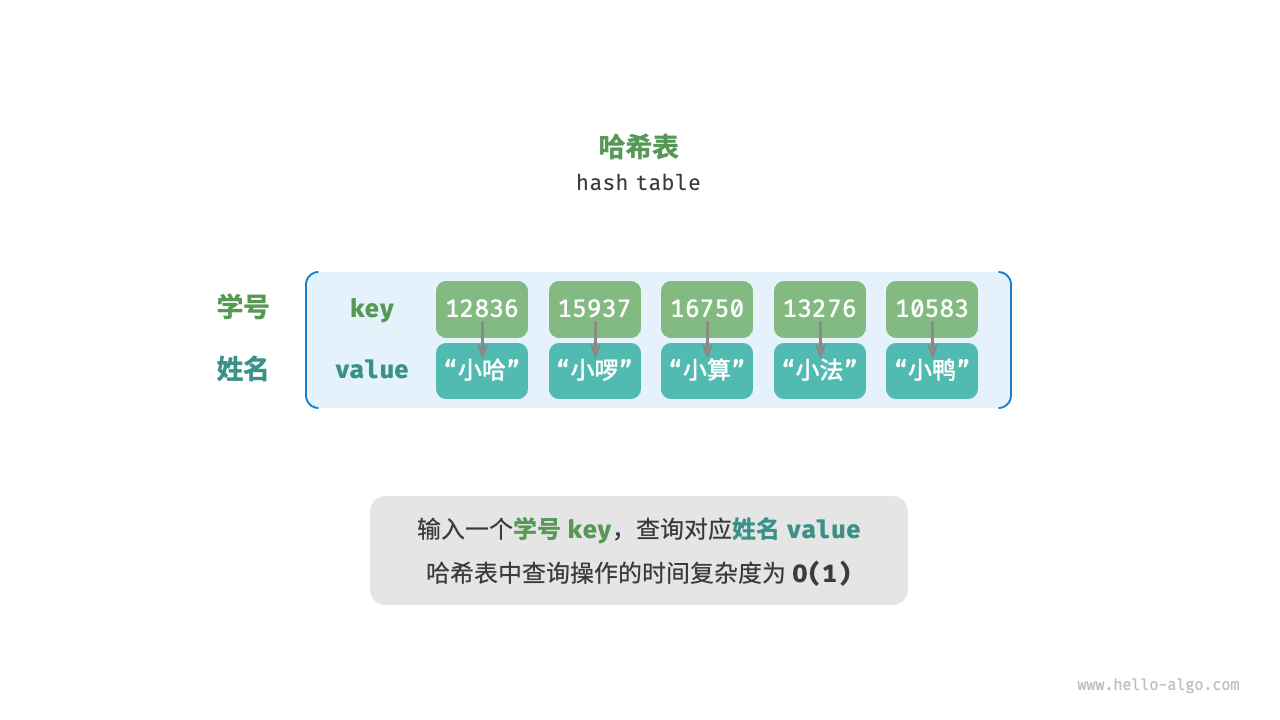
观察发现,在哈希表中进行增删查改的时间复杂度都是 ,非常高效。
哈希表简单实现
我们先考虑最简单的情况,仅用一个数组来实现哈希表。在哈希表中,我们将数组中的每个空位称为桶(bucket),每个桶可存储一个键值对。因此,查询操作就是找到 key 对应的桶,并在桶中获取 value 。
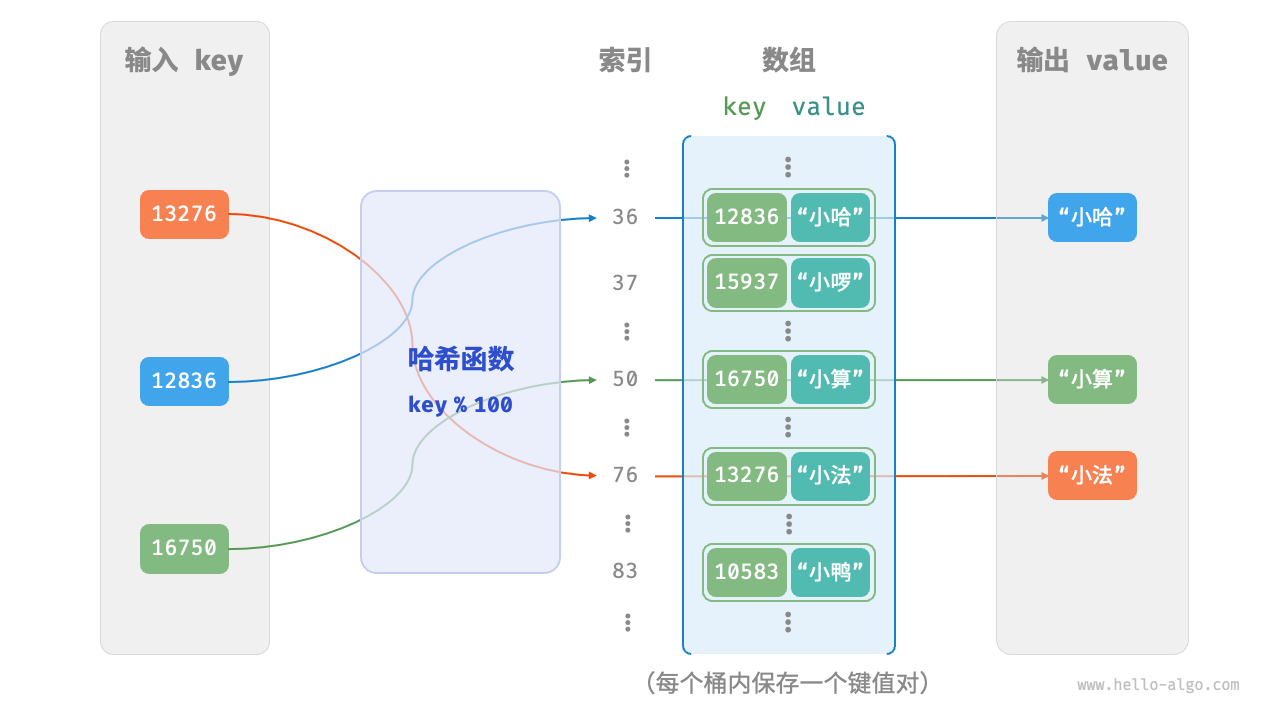
那么,如何基于 key 定位对应的桶呢?这是通过哈希函数(hash function)实现的。哈希函数的作用是将一个较大的输入空间映射到一个较小的输出空间。在哈希表中,输入空间是所有 key ,输出空间是所有桶(数组索引)。换句话说,输入一个 key ,我们可以通过哈希函数得到该 key 对应的键值对在数组中的存储位置。
-
Key 的空间:所有可能的键的集合,比如所有可能的字符串、所有可能的整数。这个集合往往非常大(甚至无限)。
-
桶(数组索引)的空间:哈希表内部数组的大小,通常是一个有限的整数范围,比如 ,那桶的索引就是 。
输入一个 key ,哈希函数的计算过程分为以下两步。
- 通过某种 Hash algorithms
hash()计算得到哈希值。 - 将哈希值对桶数量(数组长度)
capacity取模,从而获取该key对应的数组索引index。
index = hash(key) % capacity随后,我们就可以利用 index 在哈希表中访问对应的桶,从而获取 value 。
设数组长度 capacity = 100、哈希算法 hash(key) = key ,易得哈希函数为 key % 100 。下图以 key 学号和 value 姓名为例,展示了哈希函数的工作原理。
哈希冲突与扩容
从本质上看,哈希函数的作用是将所有 key 构成的输入空间映射到数组所有索引构成的输出空间,而输入空间往往远大于输出空间。因此,理论上一定存在“多个输入对应相同输出”的情况。
对于上述示例中的哈希函数,当输入的 key 后两位相同时,哈希函数的输出结果也相同。例如,查询学号为 12836 和 20336 的两个学生时,我们得到:
12836 % 100 = 36
20336 % 100 = 36如下图所示,两个学号指向了同一个姓名,这显然是不对的。我们将这种多个输入对应同一输出的情况称为哈希冲突(hash collision)。
容易想到,哈希表容量 越大,多个 key 被分配到同一个桶中的概率就越低,冲突就越少。因此,我们可以通过扩容哈希表来减少哈希冲突。
类似于数组扩容,哈希表扩容需将所有键值对从原哈希表迁移至新哈希表,非常耗时;并且由于哈希表容量 capacity 改变,我们需要通过哈希函数来重新计算所有键值对的存储位置,这进一步增加了扩容过程的计算开销。为此,编程语言通常会预留足够大的哈希表容量,防止频繁扩容。
负载因子(load factor)是哈希表的一个重要概念,其定义为哈希表的元素数量除以桶数量,用于衡量哈希冲突的严重程度,也常作为哈希表扩容的触发条件。例如在 Java 中,当负载因子超过 时,系统会将哈希表扩容至原先的 倍。