哈希表的结构改良方法主要包括“链式地址”和“开放寻址”。
链式地址
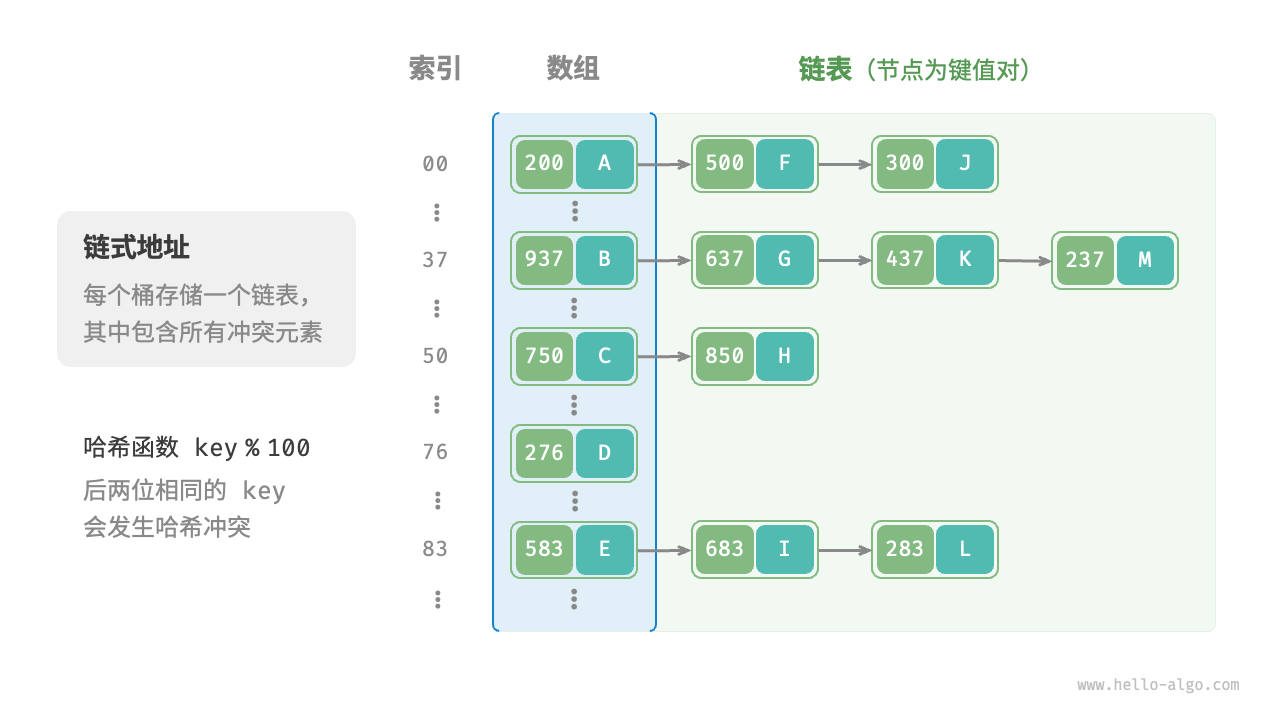
在原始哈希表中,每个桶仅能存储一个键值对。链式地址(separate chaining)将单个元素转换为链表,将键值对作为链表节点,将所有发生冲突的键值对都存储在同一链表中。下图展示了一个链式地址哈希表的例子。
开放寻址
开放寻址(open addressing)不引入额外的数据结构,而是通过“多次探测”来处理哈希冲突,探测方式主要包括线性探测、平方探测和多次哈希等。
线性探测

然而,线性探测容易产生“聚集现象”。具体来说,数组中连续被占用的位置越长,这些连续位置发生哈希冲突的可能性越大,从而进一步促使该位置的聚堆生长,形成恶性循环,最终导致增删查改操作效率劣化。
值得注意的是,我们不能在开放寻址哈希表中直接删除元素。这是因为删除元素会在数组内产生一个空桶 None ,而当查询元素时,线性探测到该空桶就会返回,因此在该空桶之下的元素都无法再被访问到,程序可能误判这些元素不存在。
为了解决该问题,我们可以采用懒删除(lazy deletion)机制:它不直接从哈希表中移除元素,而是利用一个常量 TOMBSTONE 来标记这个桶。在该机制下,None 和 TOMBSTONE 都代表空桶,都可以放置键值对。但不同的是,线性探测到 TOMBSTONE 时应该继续遍历,因为其之下可能还存在键值对。
然而,懒删除可能会加速哈希表的性能退化。这是因为每次删除操作都会产生一个删除标记,随着 TOMBSTONE 的增加,搜索时间也会增加,因为线性探测可能需要跳过多个 TOMBSTONE 才能找到目标元素。
为此,考虑在线性探测中记录遇到的首个 TOMBSTONE 的索引,并将搜索到的目标元素与该 TOMBSTONE 交换位置。这样做的好处是当每次查询或添加元素时,元素会被移动至距离理想位置(探测起始点)更近的桶,从而优化查询效率。
平方探测
平方探测与线性探测类似,都是开放寻址的常见策略之一。当发生冲突时,平方探测不是简单地跳过一个固定的步数,而是跳过“探测次数的平方”的步数,即 步。
多次哈希
顾名思义,多次哈希方法使用多个哈希函数 、、、 进行探测。