用于对一组数据按照特定顺序进行排列。
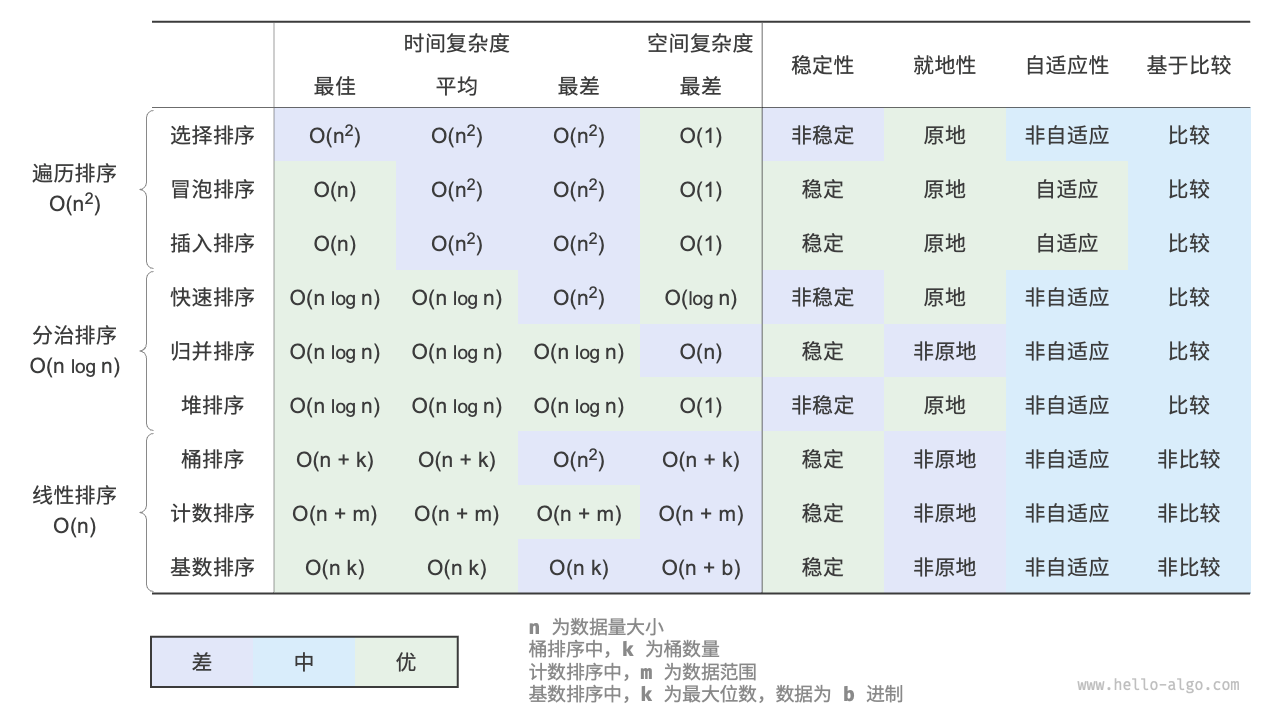
我们希望实现运行快、原地、稳定、自适应、通用性好的排序算法,这些方面是我们对排序算法的评估指标。
以下是常见排序算法:
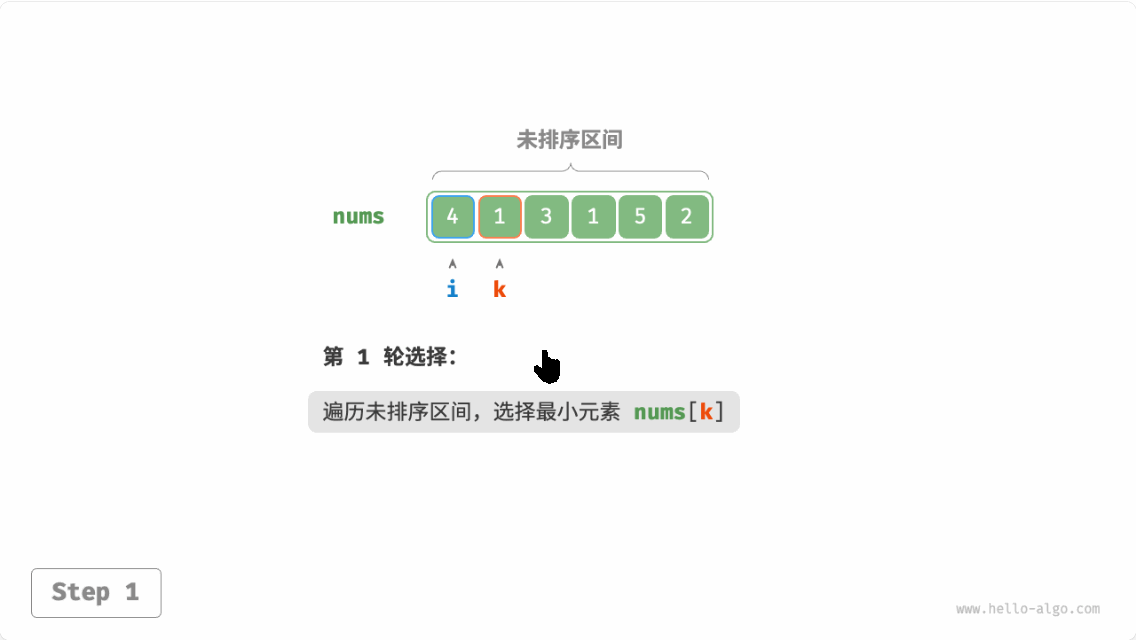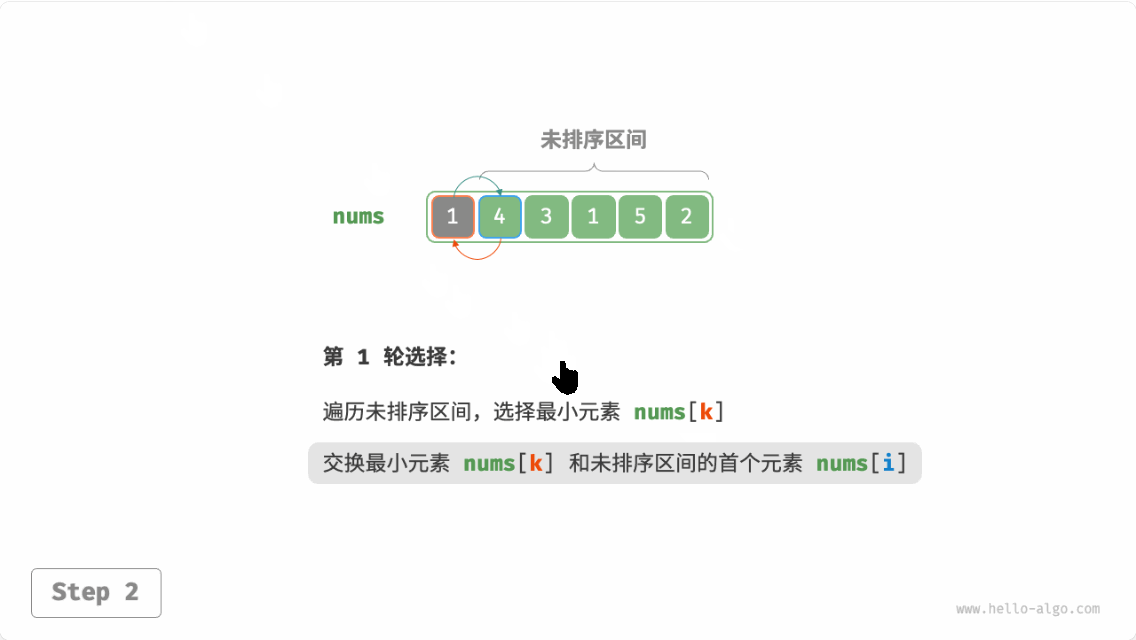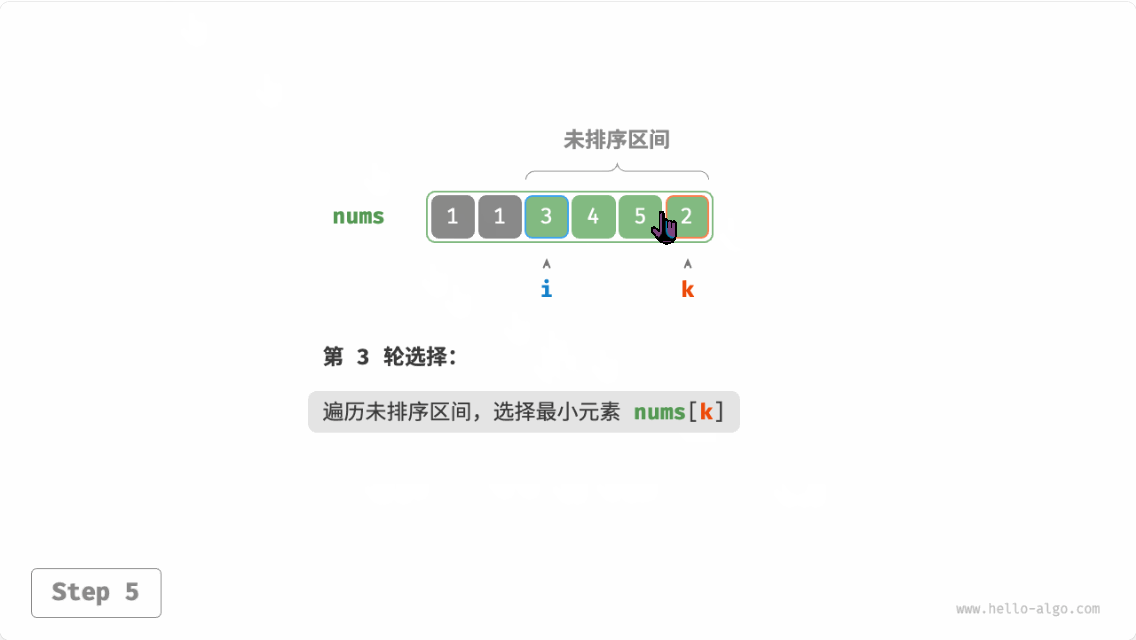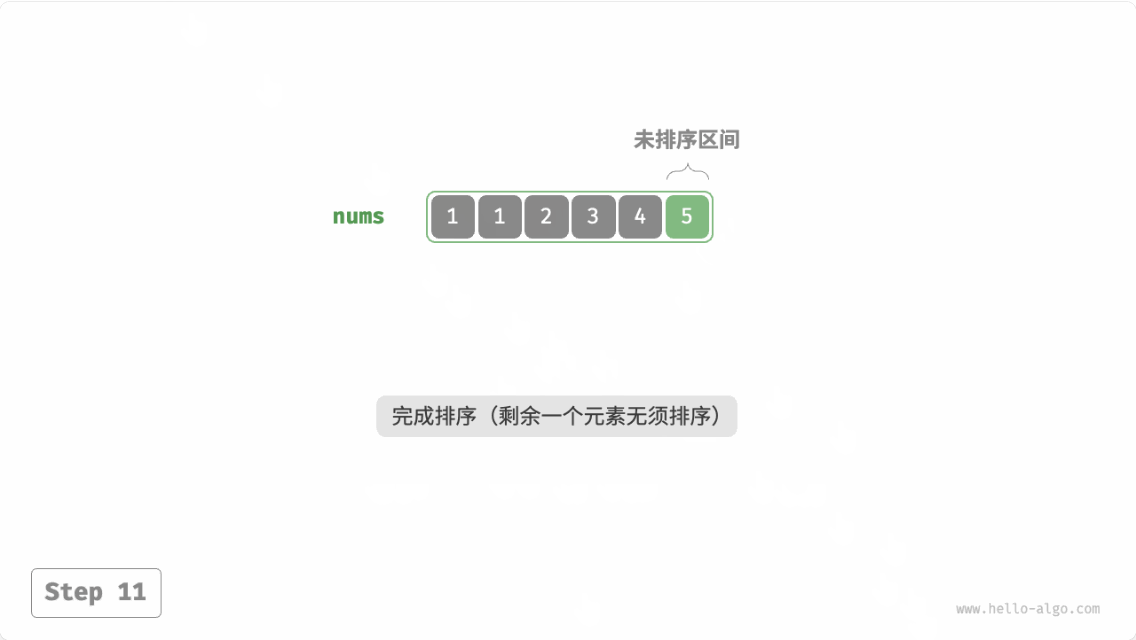
选择排序(selection sort):开启一个循环,每轮从未排序区间选择最小的元素,将其放到已排序区间的末尾。
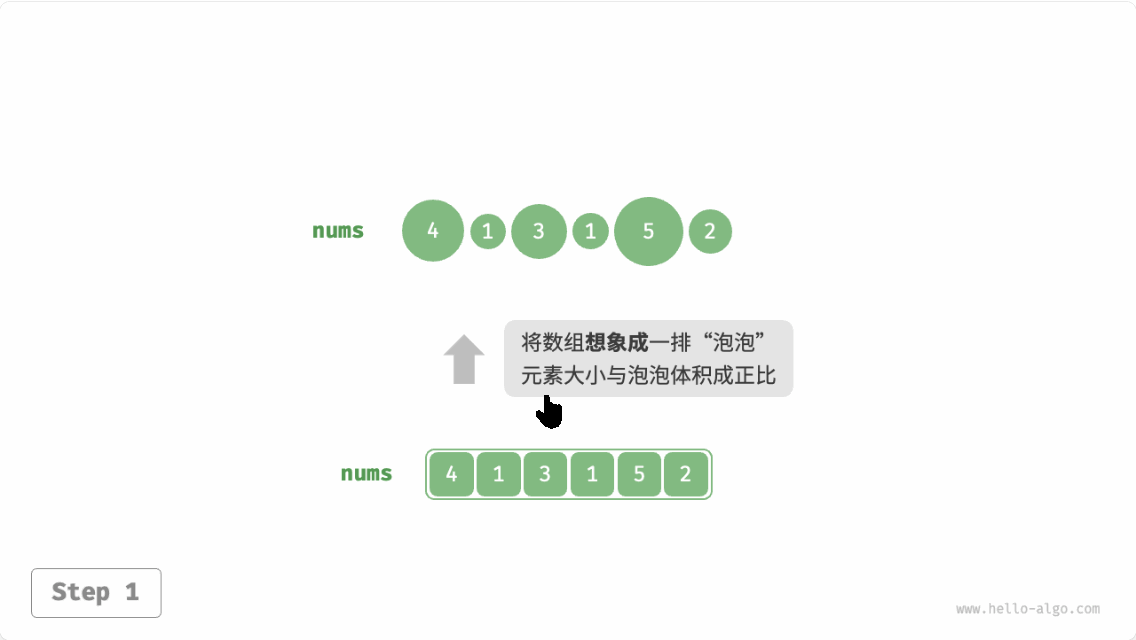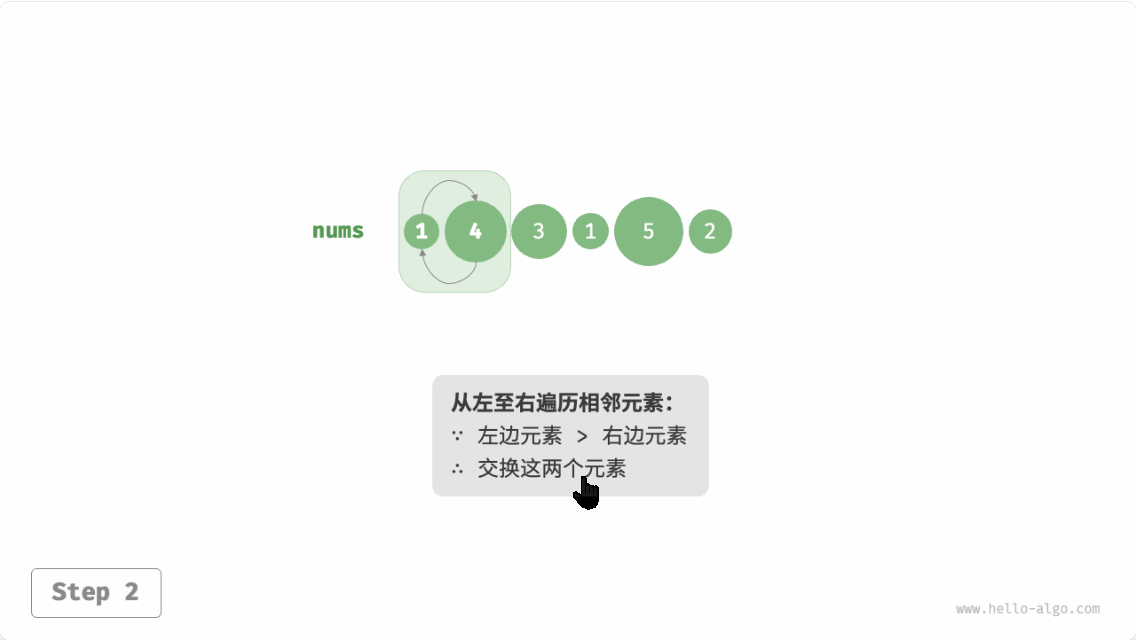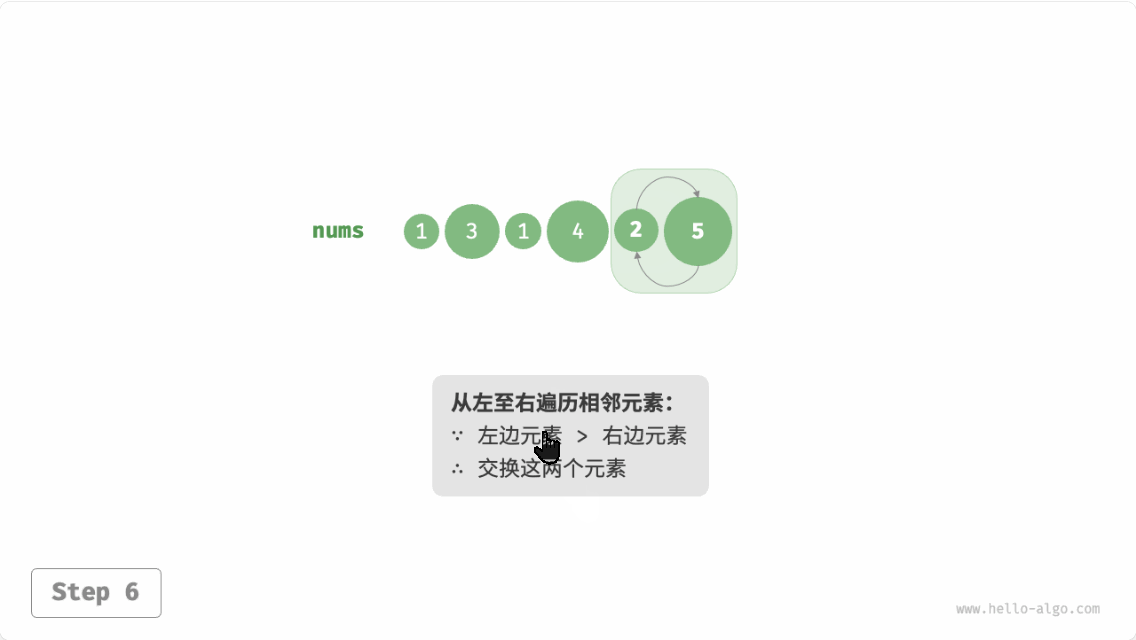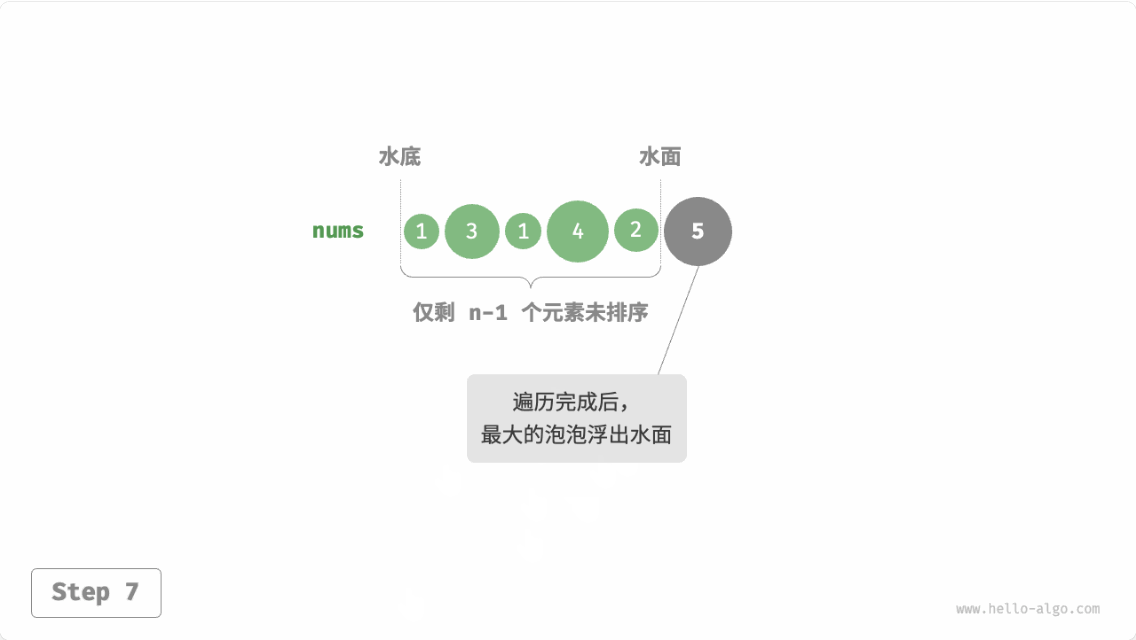
冒泡排序(bubble sort)通过连续地比较与交换相邻元素实现排序。这个过程就像气泡从底部升到顶部一样,因此得名冒泡排序。
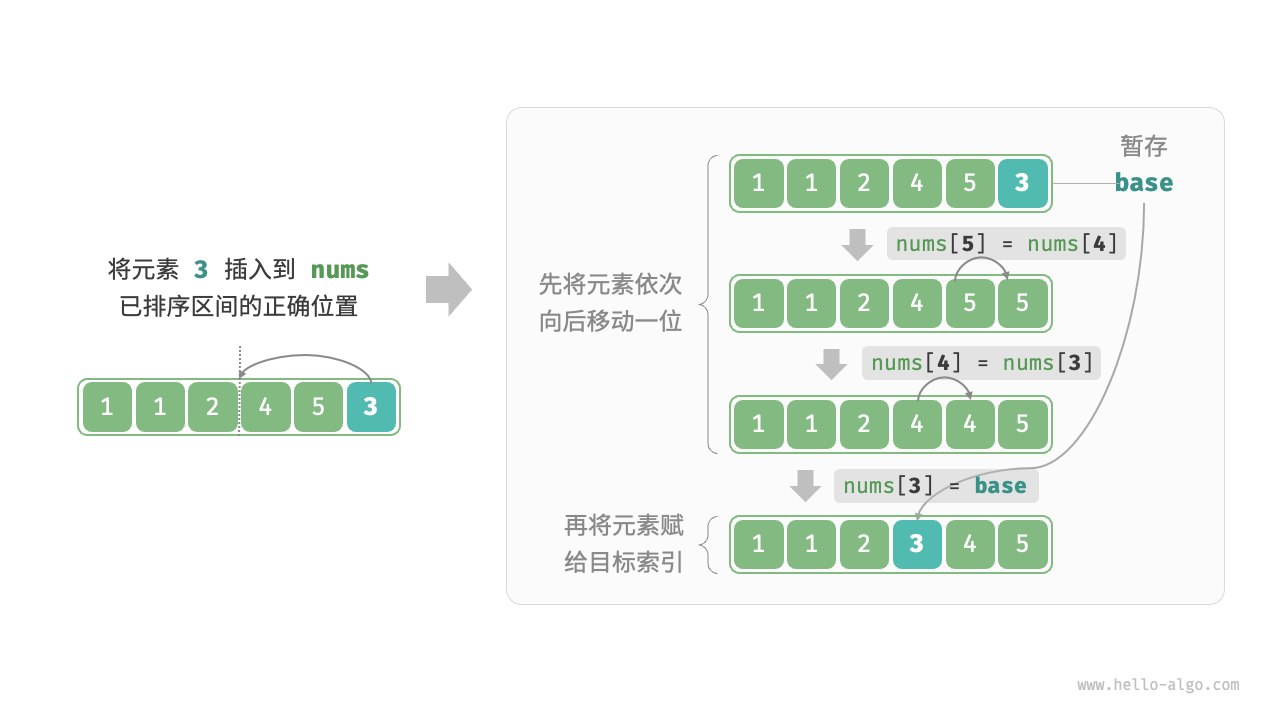
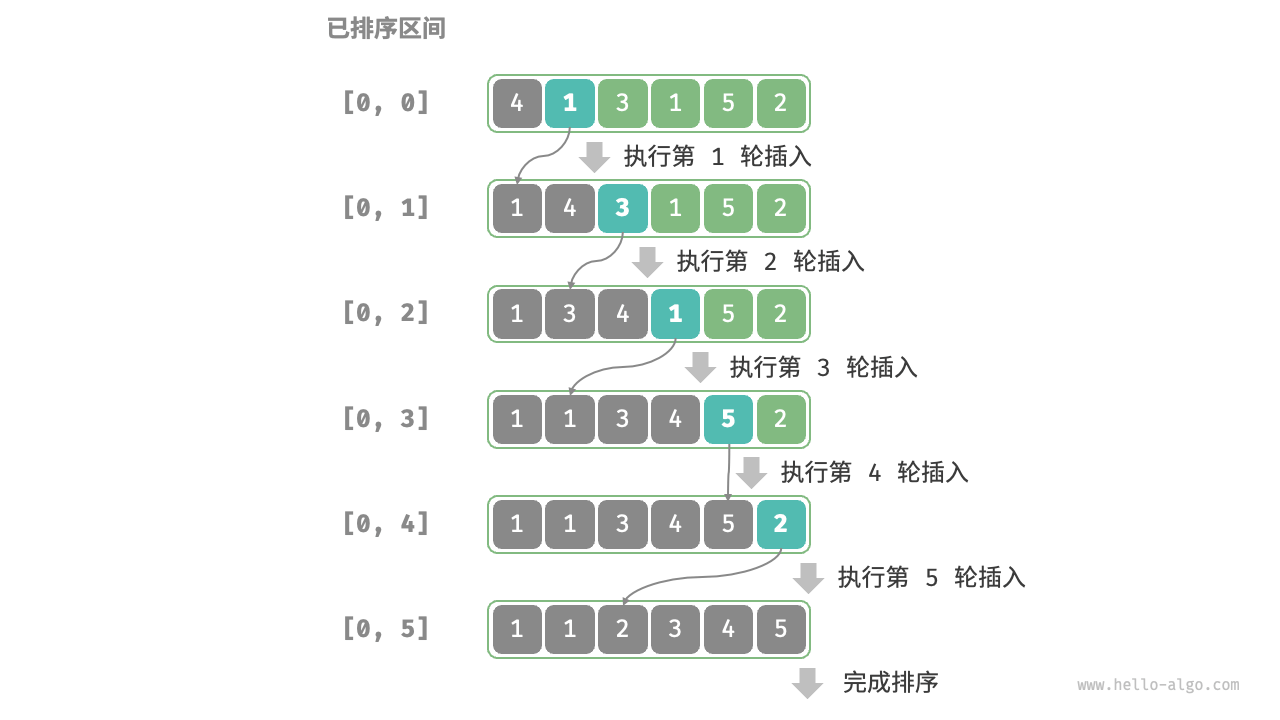
插入排序(insertion sort):在未排序区间选择一个基准元素,将该元素与其左侧已排序区间的元素逐一比较大小,并将该元素插入到正确的位置。
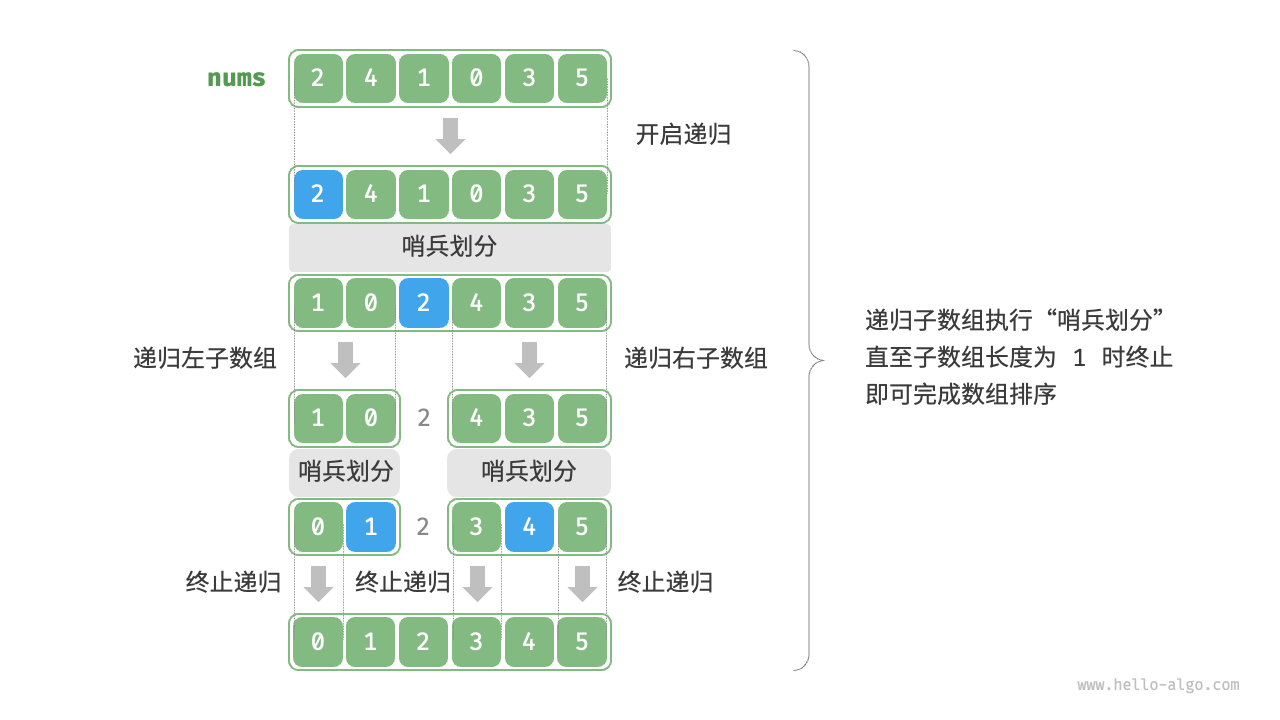
快速排序(quick sort):选择数组中的某个元素作为“基准数”,将所有小于基准数的元素移到其左侧,而大于基准数的元素移到其右侧。
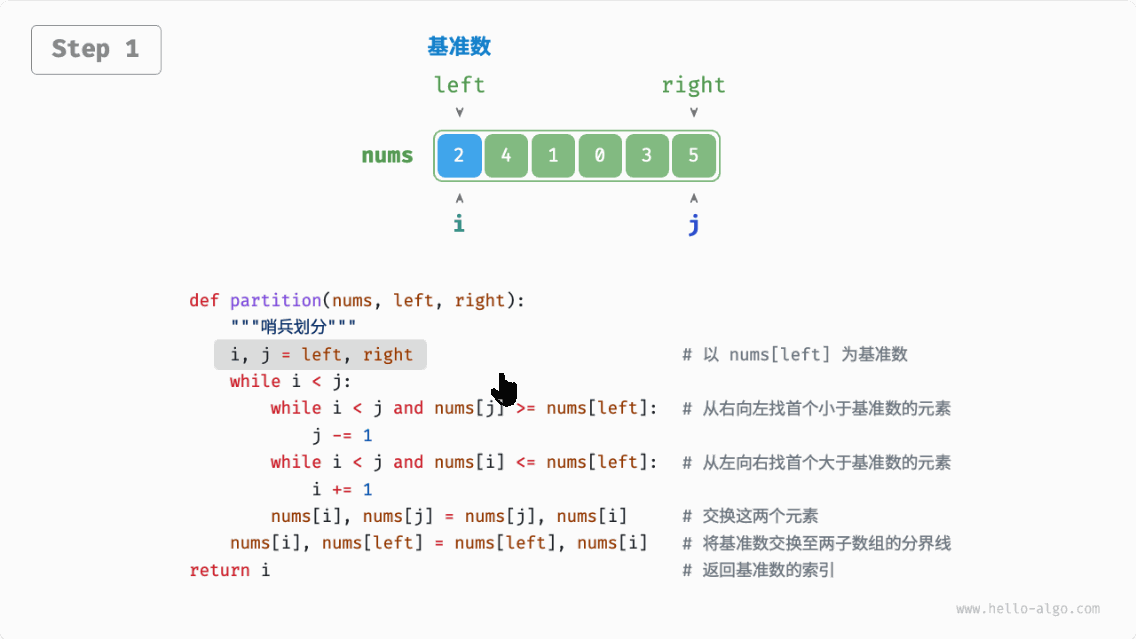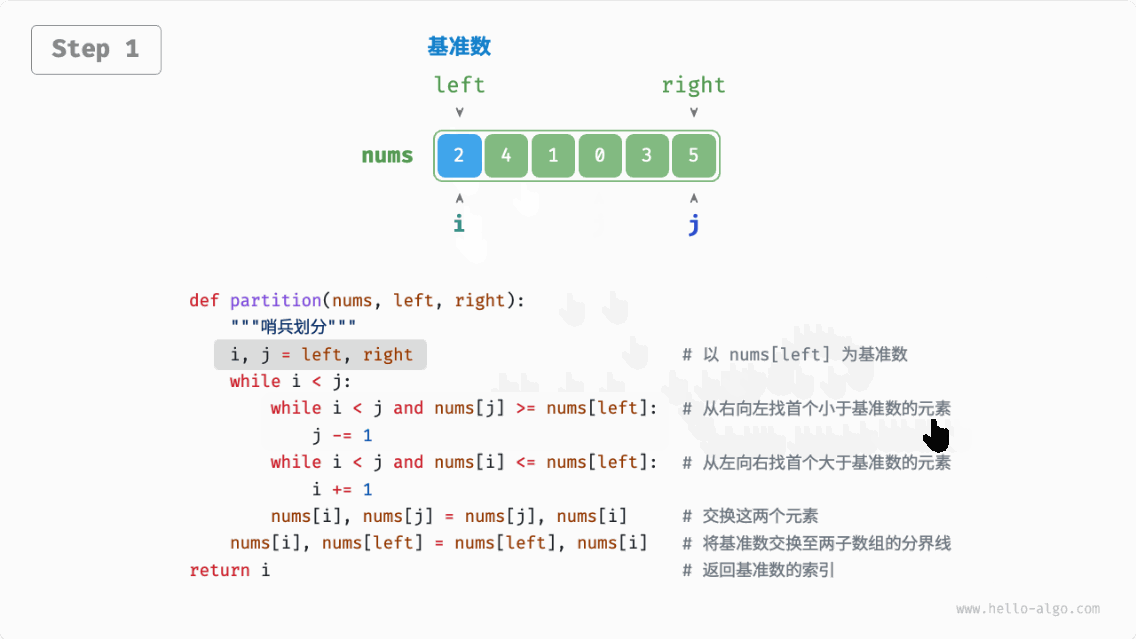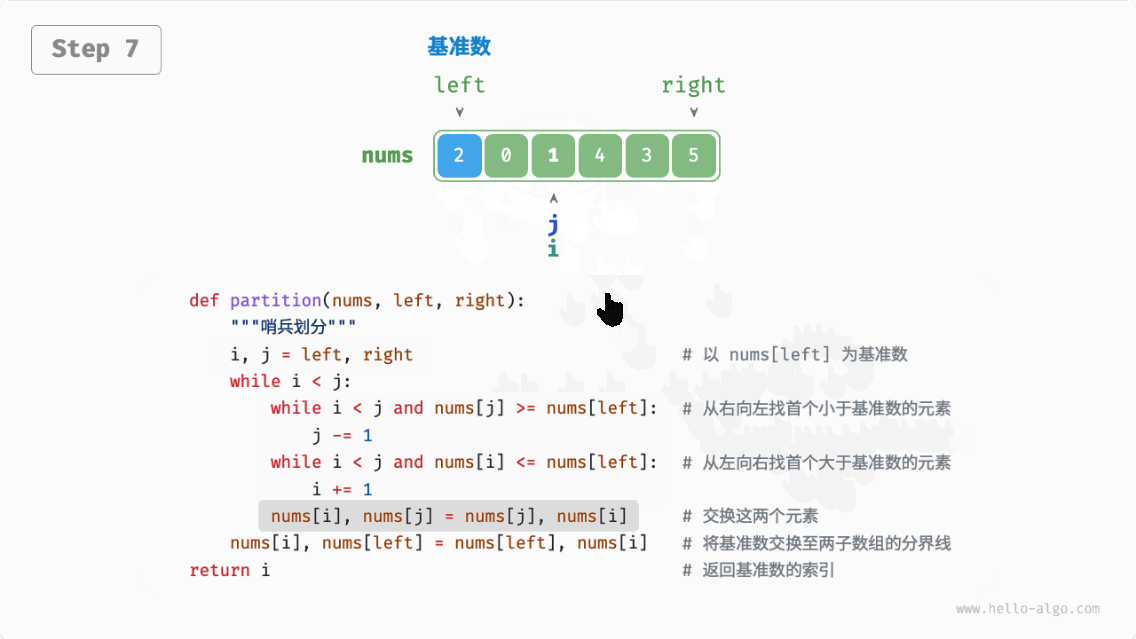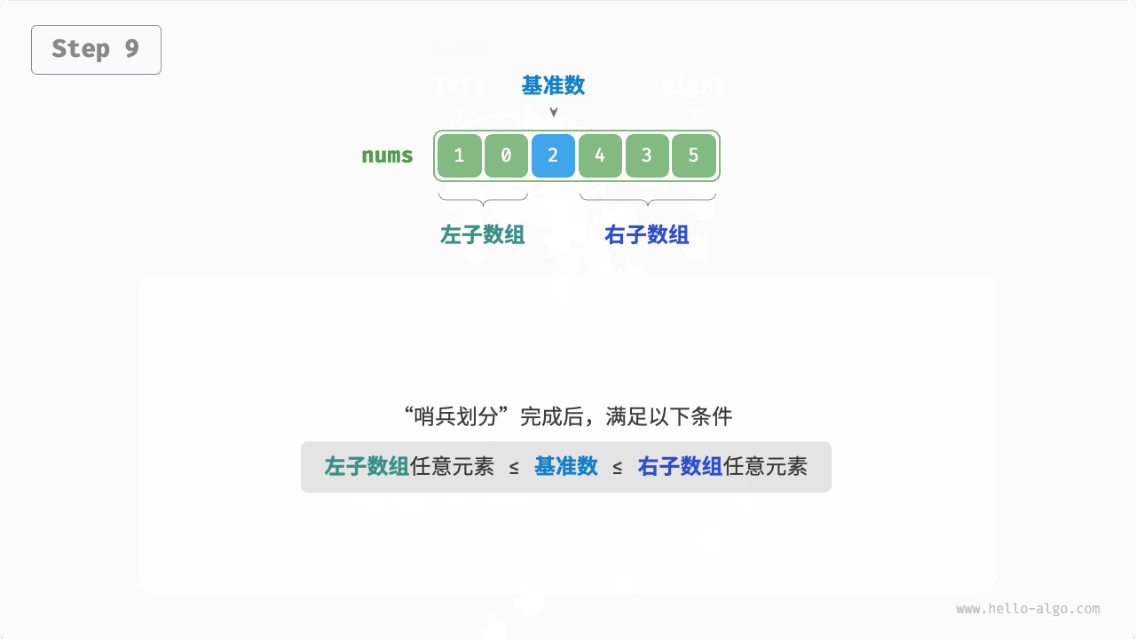
哨兵划分完成后,原数组被划分成三部分:左子数组、基准数、右子数组,且满足“左子数组任意元素 基准数 右子数组任意元素”。因此,我们接下来只需对这两个子数组进行递归排
序。
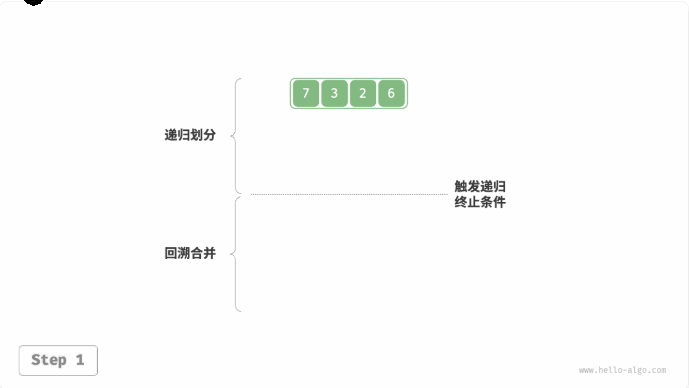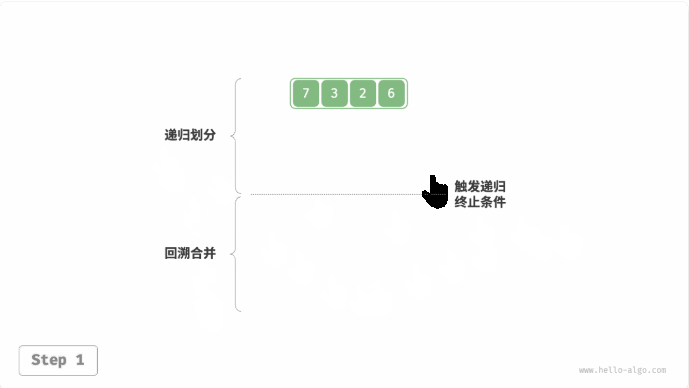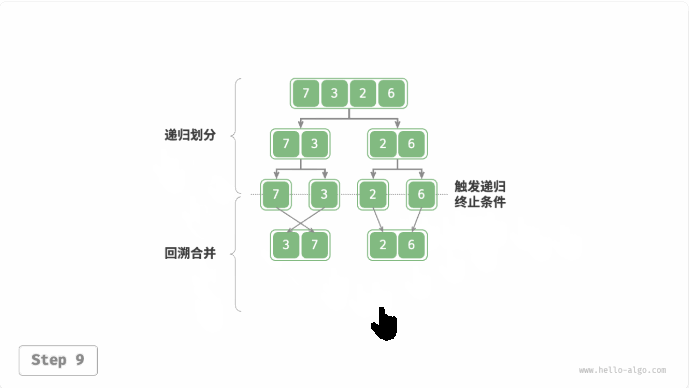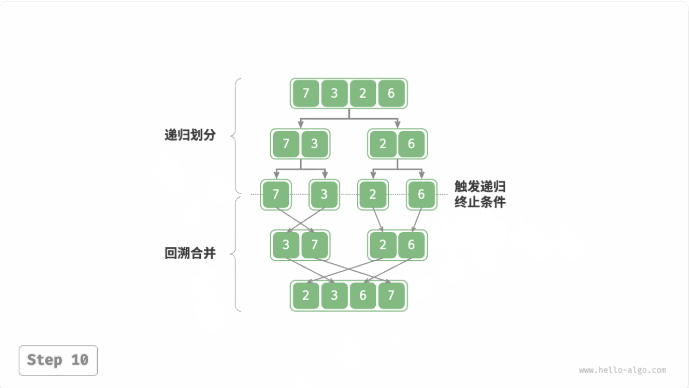
归并排序(merge sort):与二叉树后序遍历的递归顺序是一致的。
- 后序遍历:先递归左子树,再递归右子树,最后处理根节点。
- 归并排序:先递归左子数组,再递归右子数组,最后处理合并。
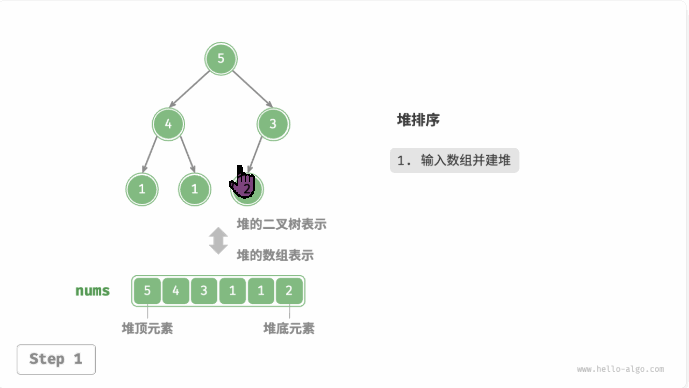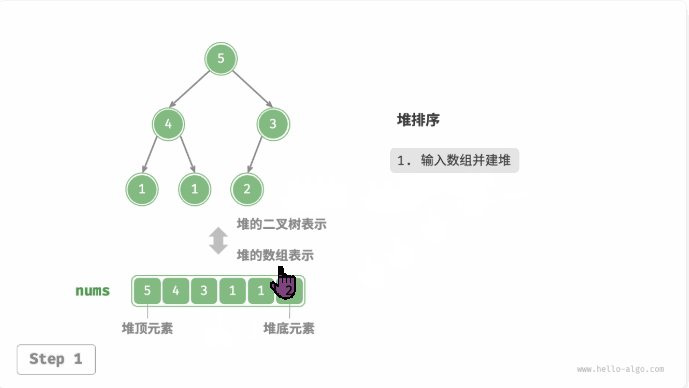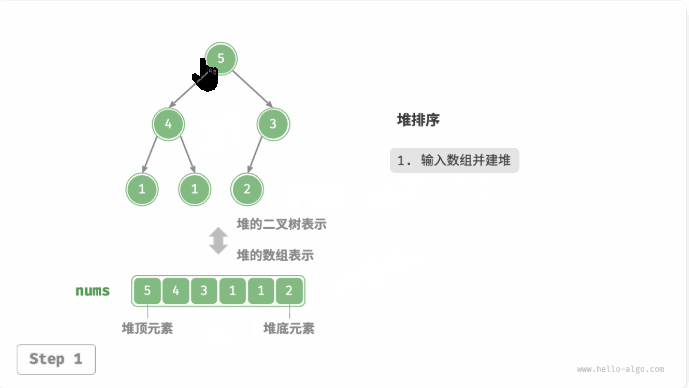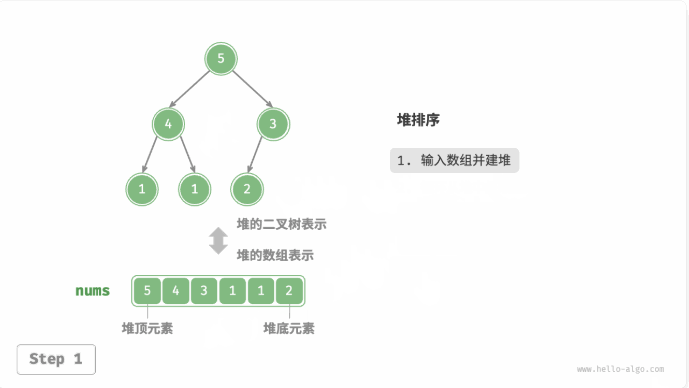
堆排序(heap sort):建立大或小顶堆,不断执行出堆操作,依次记录出堆元素,即可得到从小到大排序的序列。
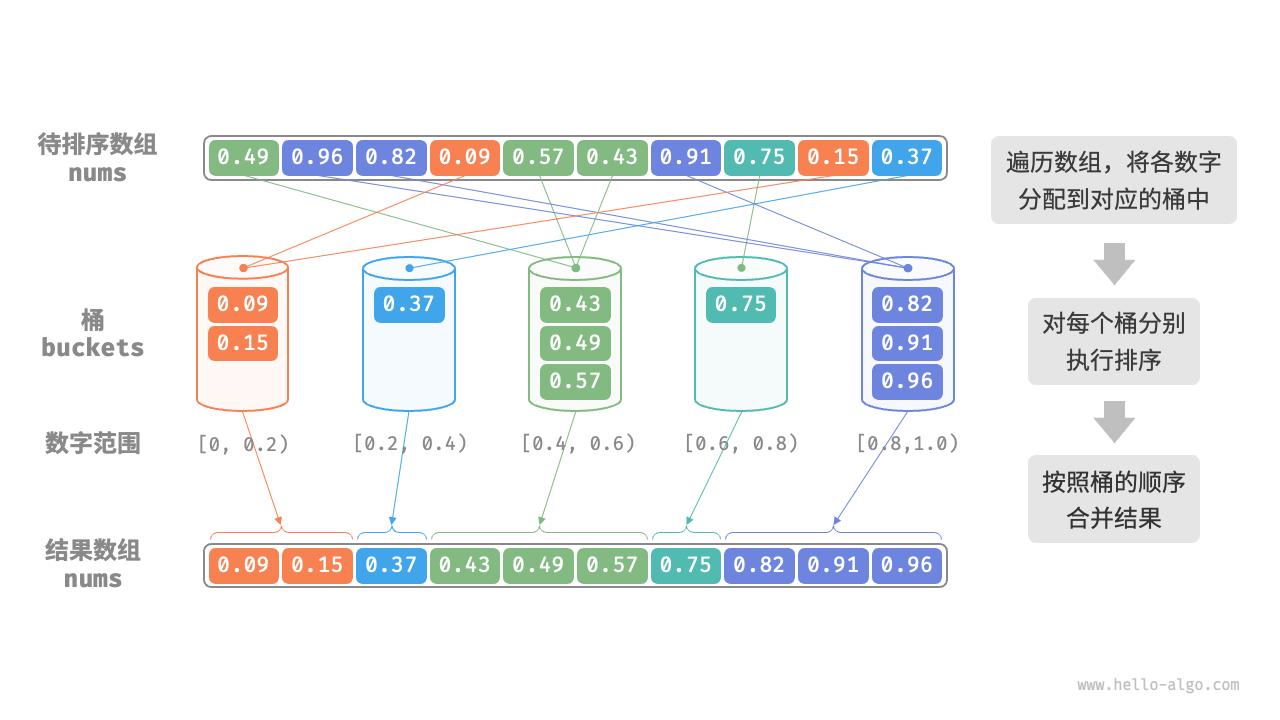
桶排序(bucket sort)是分治策略的一个典型应用。它通过设置一些具有大小顺序的桶,每个桶对应一个数据范围,将数据平均分配到各个桶中;然后,在每个桶内部分别执行排序;最终按照桶的顺序将所有数据合并。
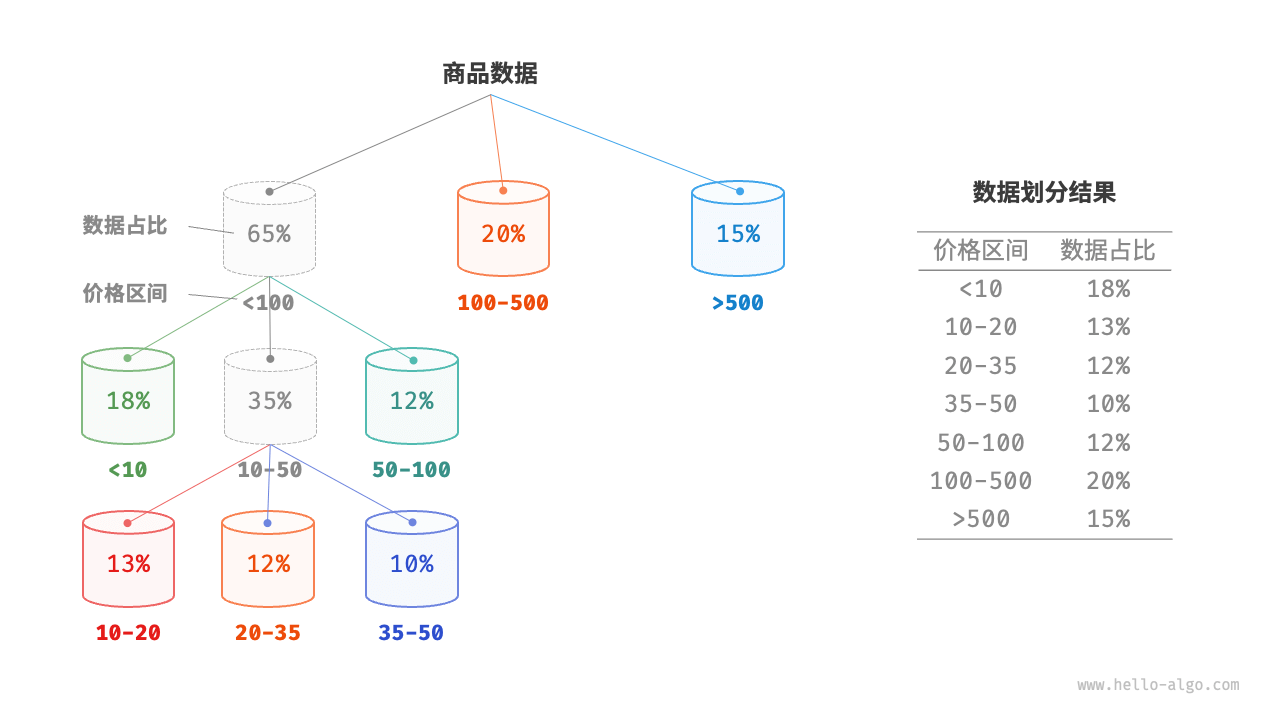
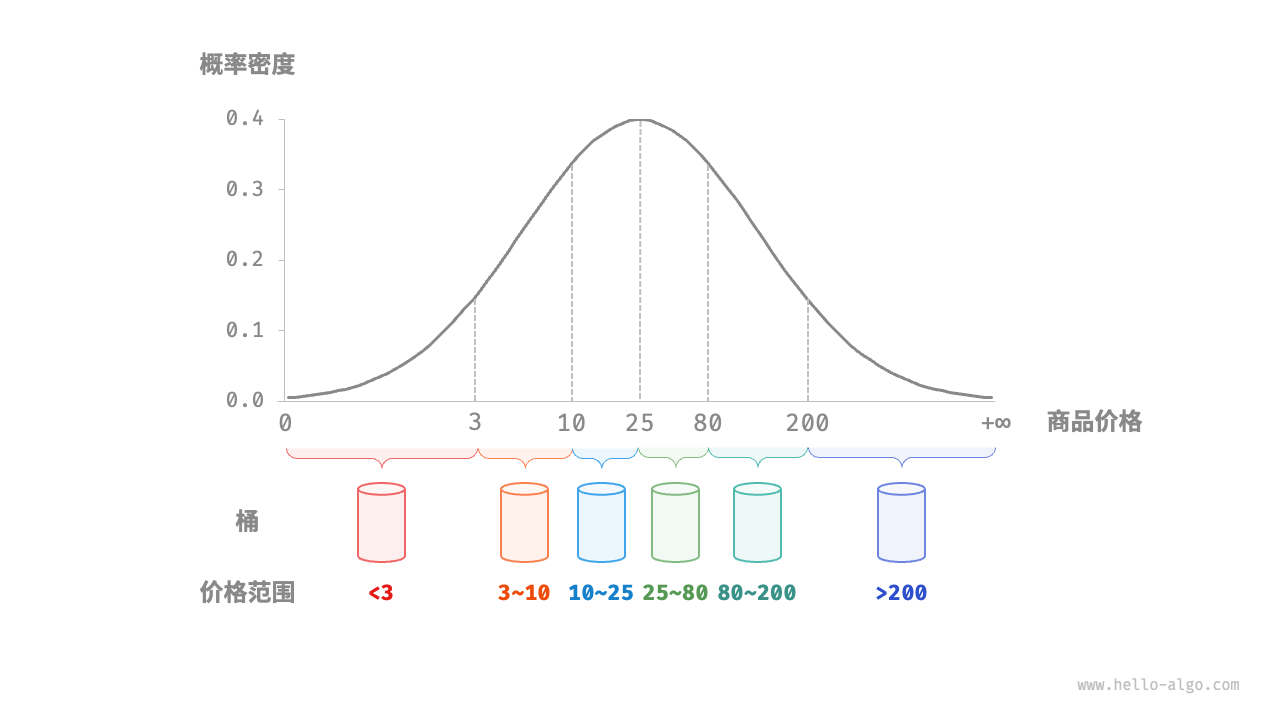
 分配细节:为实现平均分配,我们可以先设定一条大致的分界线,将数据粗略地分到 3 个桶中。分配完毕后,再将商品较多的桶继续划分为 3 个桶,直至所有桶中的元素数量大致相等。如果我们提前知道商品价格的概率分布,则可以根据数据概率分布设置每个桶的价格分界线。值得注意的是,数据分布并不一定需要特意统计,也可以根据数据特点采用某种概率模型进行近似。
分配细节:为实现平均分配,我们可以先设定一条大致的分界线,将数据粗略地分到 3 个桶中。分配完毕后,再将商品较多的桶继续划分为 3 个桶,直至所有桶中的元素数量大致相等。如果我们提前知道商品价格的概率分布,则可以根据数据概率分布设置每个桶的价格分界线。值得注意的是,数据分布并不一定需要特意统计,也可以根据数据特点采用某种概率模型进行近似。
计数排序(counting sort):通过统计元素数量来实现排序,通常应用于整数数组。
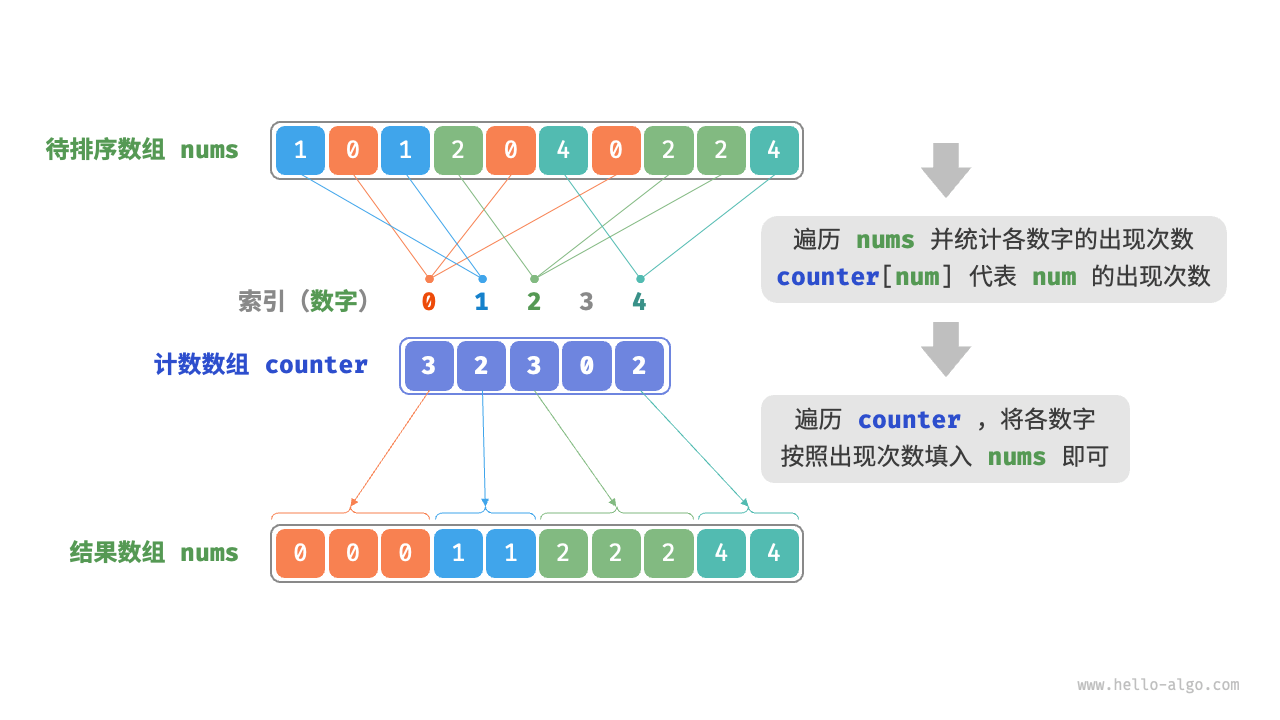
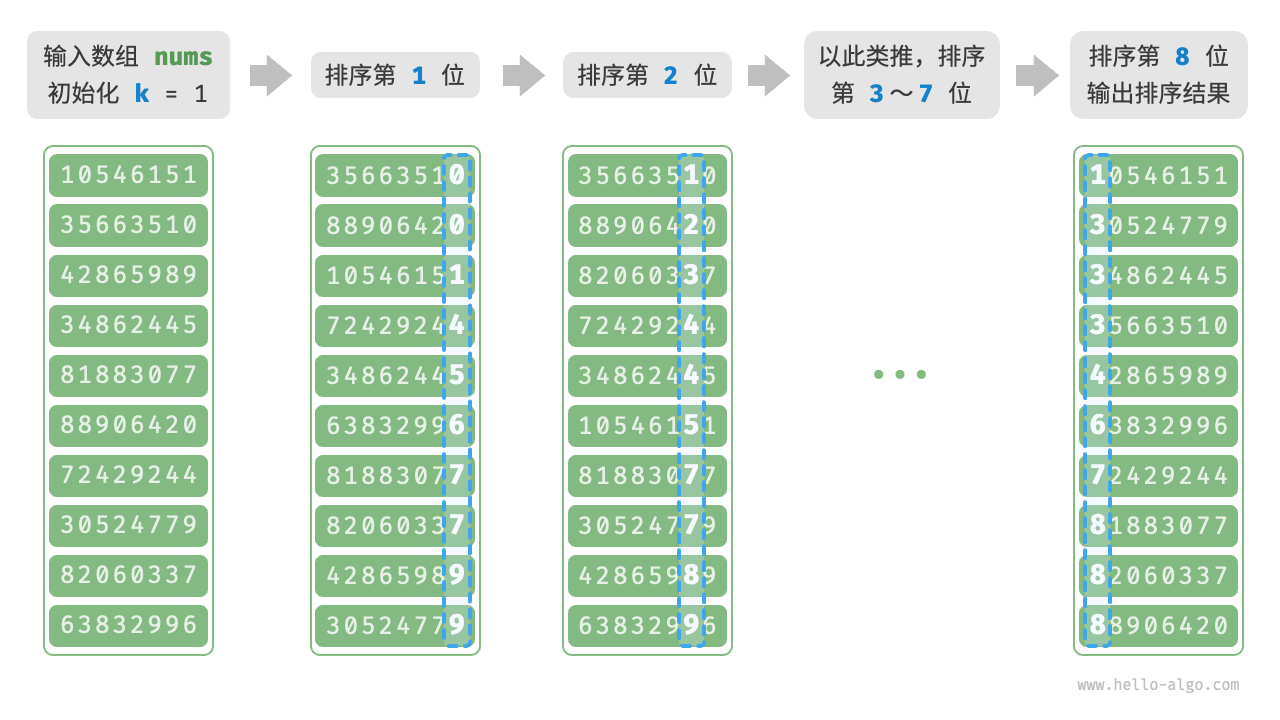
使用计数排序需要分配大量内存空间,而基数排序可以避免这种情况。基数排序(radix sort)的核心思想与计数排序一致,也通过统计个数来实现排序。在此基础上,基数排序利用数字各位之间的递进关系,依次对每一位进行排序,从而得到最终的排序结果。是桶排序的一个特例。