初始化数组
我们可以根据需求选用数组的两种初始化方式:无初始值、给定初始值。在未指定初始值的情况下,大多数编程语言会将数组元素初始化为 :
/* 初始化数组 */
// 存储在栈上
int arr[5];
int nums[5] = { 1, 3, 2, 5, 4 };
// 存储在堆上(需要手动释放空间)
int* arr1 = new int[5];
int* nums1 = new int[5] { 1, 3, 2, 5, 4 };stack是自动分配的,比较小,我们可以手动分配更大的heap来存数据,使用后手动删除。二者都被存在Random Access Memory, RAM中
访问元素
数组元素被存储在连续的内存空间中,这意味着计算数组元素的内存地址非常容易。给定数组内存地址(首元素内存地址)和某个元素的索引,我们可以使用下图所示的公式计算得到该元素的内存地址,从而直接访问该元素。
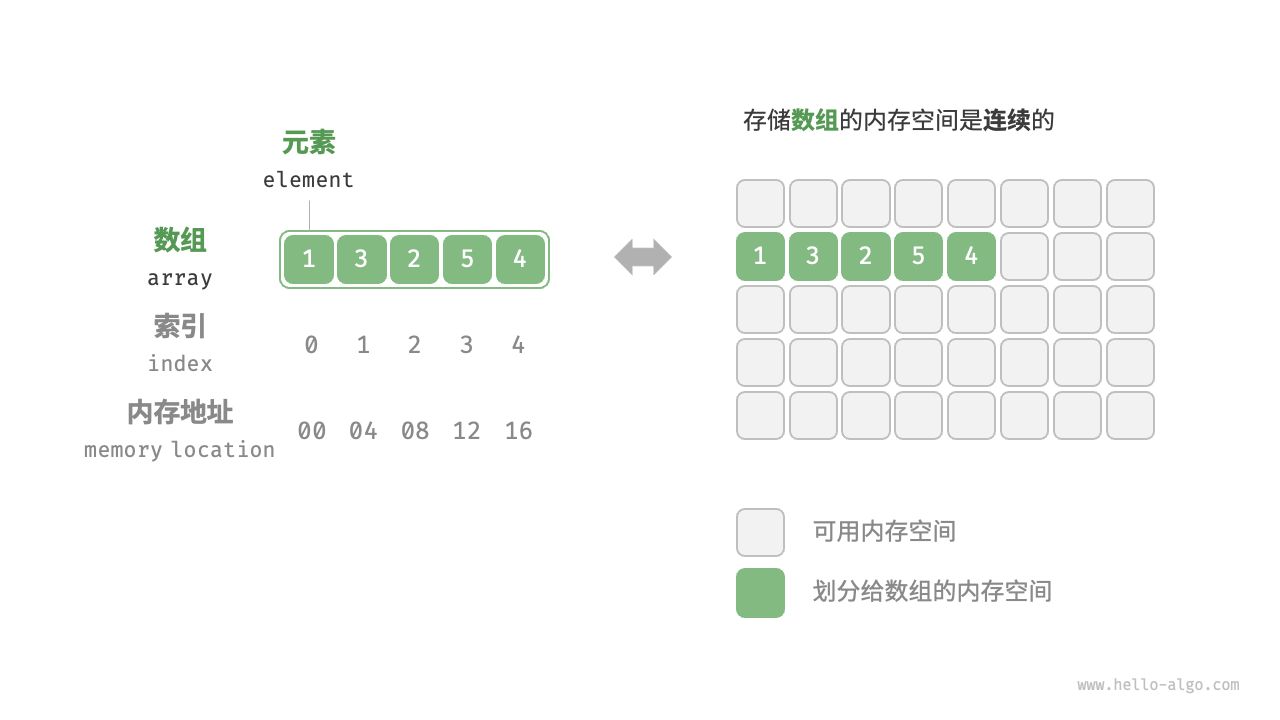
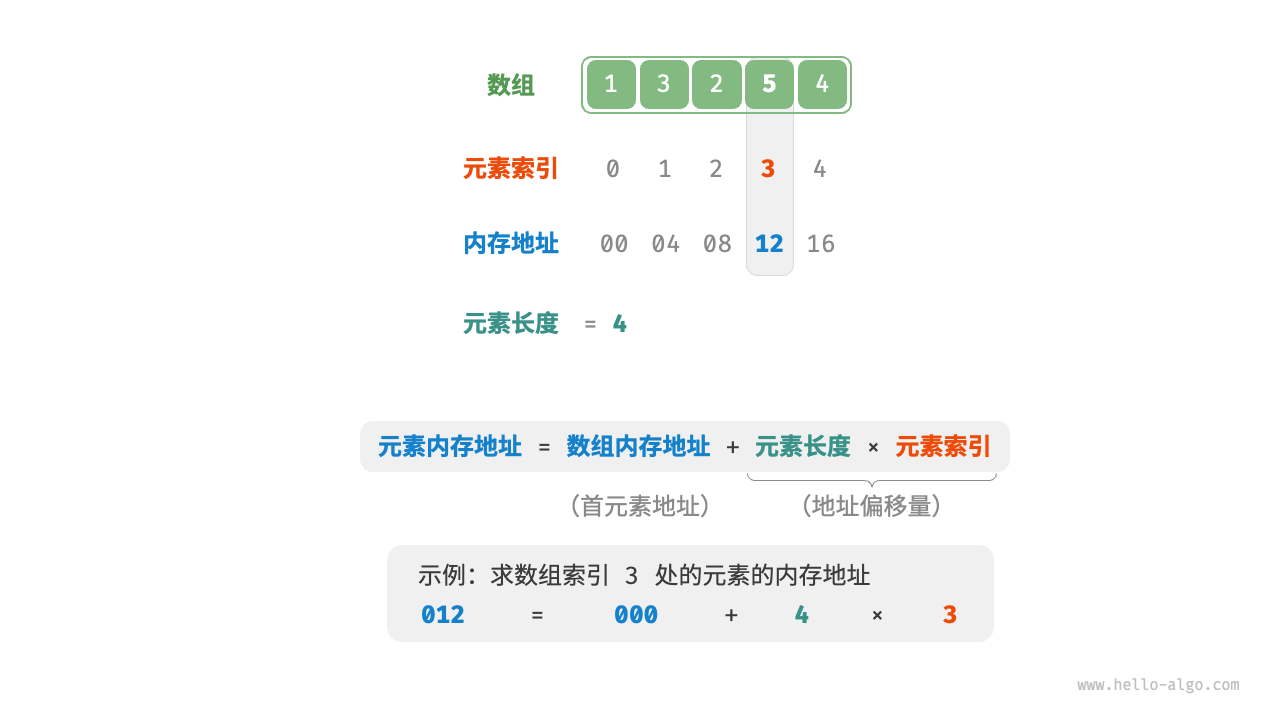
索引本质上是内存地址的偏移量。首个元素的地址偏移量是 ,因此它的索引为 。
在数组中访问元素非常高效,我们可以在 时间内随机访问数组中的任意一个元素。
在复杂的系统环境中,程序难以保证数组之后的内存空间是可用的,从而无法安全地扩展数组容量。因此在大多数编程语言中,数组的长度是不可变的。如果我们希望扩容数组,则需重新建立一个更大的数组,然后把原数组元素依次复制到新数组。这是一个 的操作,在数组很大的情况下非常耗时。
数组的优点与局限性
数组存储在连续的内存空间内,且元素类型相同。这种做法包含丰富的先验信息,系统可以利用这些信息来优化数据结构的操作效率。
- 空间效率高:数组为数据分配了连续的内存块,无须额外的结构开销。
- 支持随机访问:数组允许在 时间内访问任何元素。
- 缓存局部性:当访问数组元素时,计算机不仅会加载它,还会缓存其周围的其他数据,从而借助高速缓存来提升后续操作的执行速度。
连续空间存储是一把双刃剑,其存在以下局限性。
- 插入与删除效率低:当数组中元素较多时,插入与删除操作需要移动大量的元素。
- 长度不可变:数组在初始化后长度就固定了,扩容数组需要将所有数据复制到新数组,开销很大。
- 空间浪费:如果数组分配的大小超过实际所需,那么多余的空间就被浪费了。
数组典型应用
数组是一种基础且常见的数据结构,既频繁应用在各类算法之中,也可用于实现各种复杂数据结构。
- 随机访问:数组 定位,链表要 遍历 → 数组更快。如果我们想随机抽取一些样本,那么可以用数组存储,并生成一个随机序列,根据索引实现随机抽样。
- 排序和搜索:算法要求 连续存储 + 索引访问,数组正好符合。快速排序、归并排序、二分查找等都主要在数组上进行。
- 查找表:ASCII 码就是整数索引,数组映射最自然。假如我们想实现字符到 ASCII 码的映射,则可以将字符的 ASCII 码值作为索引,对应的元素存放在数组中的对应位置。
- 机器学习:矩阵运算是核心,数组直接支持高效的批量线性代数。神经网络中大量使用了向量、矩阵、张量之间的线性代数运算,这些数据都是以数组的形式构建的。数组是神经网络编程中最常使用的数据结构。
- 数据结构实现:数组可以用于实现栈、队列、哈希表、堆、图等数据结构。例如,图的邻接矩阵表示实际上是一个二维数组。
-
栈/队列:用数组存储 + 指针维护下标即可。
-
堆:用数组表示二叉树(父子节点可直接用下标关系)。
-
图邻接矩阵:二维数组天然表示点与点的关系。
-
当使用数组实现列表时,长度不可变的性质会导致列表的实用性降低。这是因为我们通常无法事先确定需要存储多少数据,从而难以选择合适的列表长度。若长度过小,则很可能无法满足使用需求;若长度过大,则会造成内存空间浪费。
为解决此问题,我们可以使用动态数组(dynamic array)来实现列表。它继承了数组的各项优点,并且可以在程序运行过程中进行动态扩容。
实际上,许多编程语言中的标准库提供的列表是基于动态数组实现的,例如 Python 中的 list 、Java 中的 ArrayList 、C++ 中的 vector 和 C# 中的 List 等。