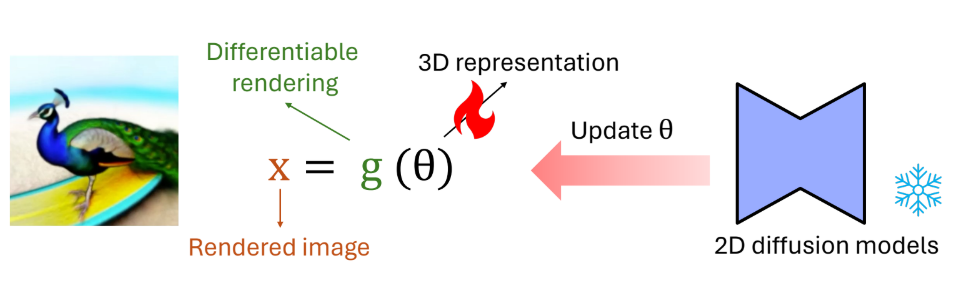
假设 3D 表示为 Θ,渲染得到的图像为 X(通过某种渲染函数 G),目标是用预训练的 2D 扩散模型去更新 3D 表示 Θ,使得渲染结果 X 符合给定的指令(无论是文本提示还是图像提示)。
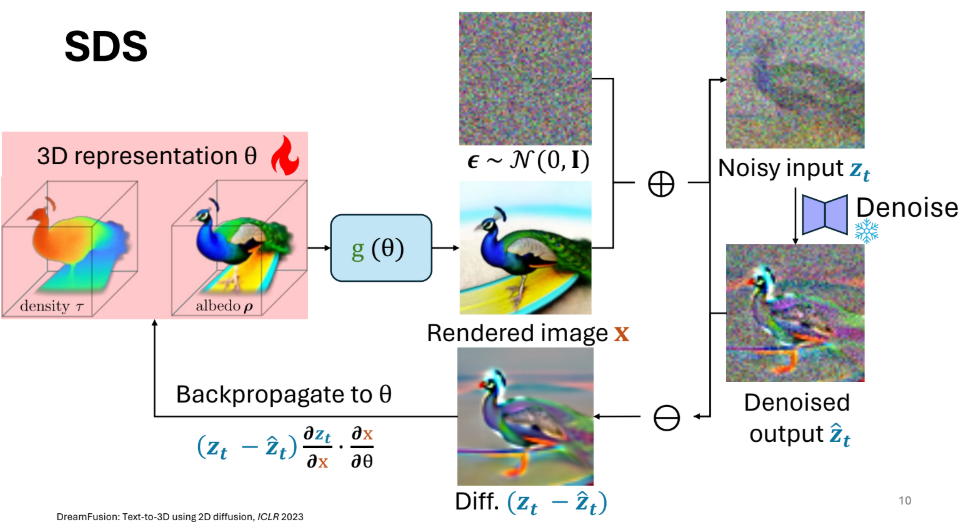
一种这样的优化方法称为 Score Distillation Sampling(简称 SDS)。SDS 的步骤是:从 3D 表示 Θ 渲染图像,向图像添加噪声,然后对图像去噪;去噪前后图像的残差即为一个评分(score),该评分被反向传播回 3D 表示 Θ。在左侧我们可视化了对象的 SDS 优化过程,右侧展示了若干最终优化得到的 3D 结果示例。
然而,SDS 优化的一个问题是:即使是用文本提示,SDS 通常也只能生成单一模态的 3D 对象,换言之缺乏多样性。为改进 SDS 的一个方向是为一个文本提示生成多样的结果。为实现这一点,与其只优化单一点 Θ,不如去学习 Θ 的分布(记作 μ),通过从该分布采样 Θ 来生成多样结果。人们用变分推断(variational inference)来学习这个分布。基本上我们可以从学到的 Θ 分布中得到一组渲染图像,这些渲染图像代表变分分布,目标是将这变分分布匹配到由预训练 2D 扩散模型所输出的目标分布(这里我们假设预训练的 2D 扩散模型给出目标分布)。
那么下个问题是如何优化这个分布匹配。直接去匹配两个分布是有挑战的,因为图像位于复杂的高维空间;相比之下,在噪声分布上进行优化更可行,因为噪声分布是已知且预定义的。因此,优化目标可以改为在各个时间步上匹配噪声分布,使得训练过程更可控、更有效。