简化模型,防止想太多过拟合,在新数据上判断错误。
-
L2 正则化(Ridge):
对应 Maximum A Posteriori Estimation, MAP,等价于给参数加上高斯先验。
-
惩罚权重的平方,尤其重罚大权重;优化会把信息分散到多个较小权重上,少出现精确为 0 的系数。
-
等惩罚集合是圆(或椭球),最优解常落在圆的边上,导致权重缩小但不为 0。
-
L1 正则化(Lasso):
对应给参数加上 Laplace 先验,能产生稀疏解。
-
惩罚权重绝对值,促使不重要的权重变为 精确 0,实现特征选择(稀疏)。
-
等惩罚集合是菱形,最优解常落在坐标轴上(某些坐标为 0)。
Elastic Net
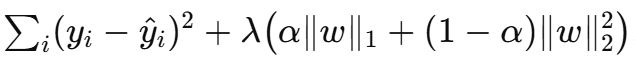
把 L1 的稀疏性和 L2 的稳定性结合起来
- Maximum Likelihood Estimation, MLE倾向于选择复杂模型;
- **Maximum A Posteriori Estimation, MAP= MLE + 正则化(相当于引入先验约束)。
Dropout
-
是什么:训练时以概率 ppp 随机把神经元输出置为 0(或按概率保留 1−p1-p1−p);测试时按保留概率缩放或用完整网络。
-
直观机制:相当于在训练期间随机抽取并共享大量子网络,减少神经元间的“共适应”(co-adaptation),形成模型集合的近似平均。
Batch Normalization(BN)
-
是什么:对 mini-batch 内每个通道做规范化 x^=(x−μbatch)/σbatch\hat x=(x-\mu_{\text{batch}})/\sigma_{\text{batch}}x^=(x−μbatch)/σbatch,再用可学习的尺度/偏置 γ,β\gamma,\betaγ,β 变换。
-
直观机制:把每层输入分布稳定到相似尺度,减少训练时参数敏感性,允许用更大学习率、加速收敛。训练时使用 batch 统计,推理时用 running mean/var。
Stochastic Depth(随机深度 / 层级丢弃)
-
是什么:训练时以某概率跳过(直接恒等连接)整个残差块(或层),测试时使用完整网络(或按期望缩放)。
-
直观机制:类似为不同深度的子网络做集成,减轻非常深网络的训练难度并正则化(避免某些层过度拟合)。
Fractional Pooling / Stochastic Pooling
-
Fractional Max-Pooling(分数下采样):
-
是什么:允许非整数比例的下采样(例如从尺寸 WWW 到 αW \alpha WαW),通过随机/可变的 pooling 区域拆分来实现,每次前向选择稍微不同的采样格局。
-
直观机制:引入随机性和更多的平移不变性,减少池化固定格局导致的信息丢失过拟合。
-
应用/效果:在一些早期工作里提升泛化,但实现复杂,后来被更简单的替代(strided conv, adaptive pooling, avg pool)广泛取代。
-
-
Stochastic Pooling(随机池化):
-
是什么:在一个池化窗口内按激活值概率随机选择一个位置作为输出(而非 max 或 avg)。
-
直观机制:在池化层引入噪声,作为正则化手段;也把注意力放在强响应位置上但有随机性。
-