引入“弯曲”,网络能拟合更复杂的函数,比如人脸识别、语音识别。
分类
- 饱和型:输入太大或太小会“卡死”,梯度很小(如 Sigmoid、Tanh)。
- 非饱和型:不会轻易卡死,梯度消失少(如 ReLU、Leaky ReLU、ELU)。
| 函数 | 输出范围 | 是否零中心 | 是否梯度消失 | 计算速度 | 典型用途 |
|---|---|---|---|---|---|
| Sigmoid | 0~1 | 否 | 是 | 慢 | 二分类概率输出 |
| Tanh | -1~1 | 是 | 是 | 慢 | 隐藏层(早期) |
| ReLU | 0~∞ | 否 | 否(正区间) | 快 | 隐藏层常用 |
| LeakyReLU | 负小值~∞ | 否 | 否 | 快 | 解决死 ReLU |
| PReLU | 负小值~∞ | 否 | 否 | 快 | 自动调负区间斜率 |
| ELU | 负值~∞ | 是 | 否 | 慢 | 收敛更快 |
| SELU | 负值~∞ | 是 | 否 | 中 | 自归一化网络 |
| Swish | 负值~∞ | 部分 | 否 | 中 | 高性能模型 |
| Mish | 负值~∞ | 部分 | 否 | 慢 | 高性能模型 |
| Softmax | 0~1(概率) | 否 | - | 中 | 多分类输出 |
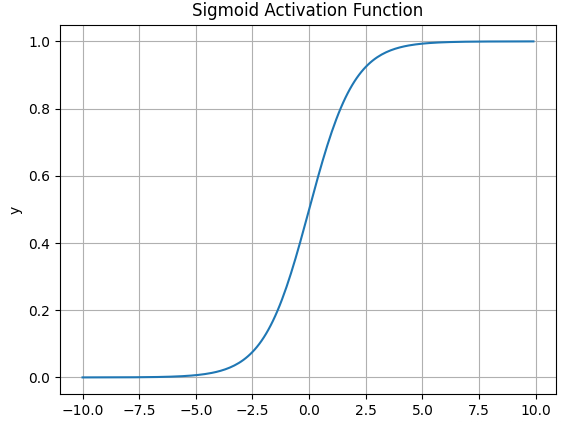
4.1 Sigmoid
公式:
特点:
- 输出范围
- 常用于二分类输出(概率) 缺点:
- 梯度消失
- 输出不是零中心
- 计算慢(要做指数运算)
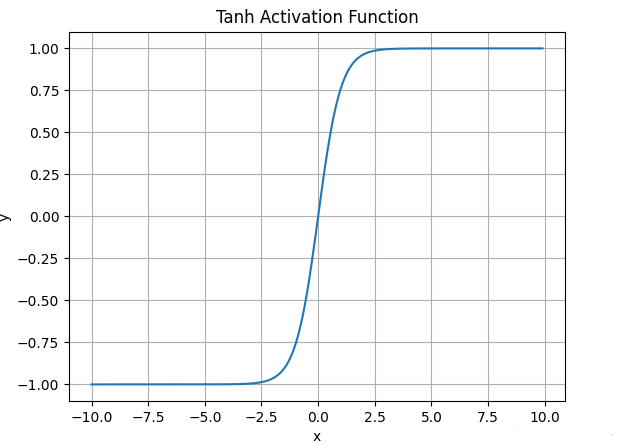
4.2 Tanh
公式:
特点:
- 输出范围
- 零中心,比 Sigmoid 好 缺点:
- 还是会梯度消失
- 计算也要指数运算
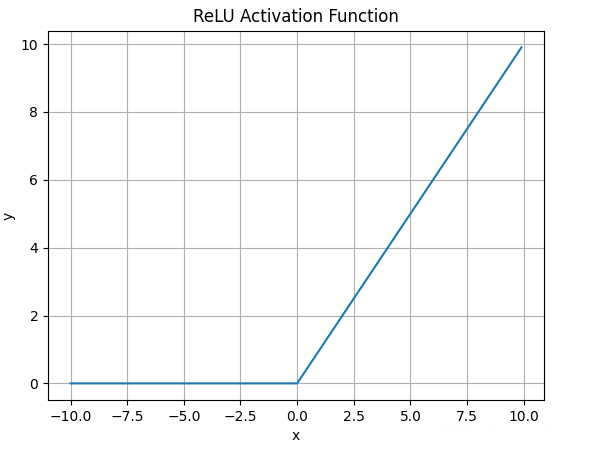
4.3 ReLU
公式:
特点:
- 简单高效,收敛快
- 不会梯度消失(正区间) 缺点:
- Dead ReLU:输入负数时梯度为 0,神经元可能永远不更新
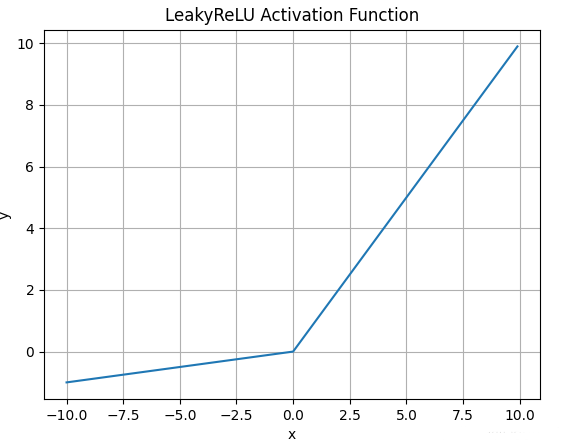
4.4 Leaky ReLU
公式:
特点:
- 负数时也留一点梯度,不会完全死掉 缺点:
- 需要手动设定
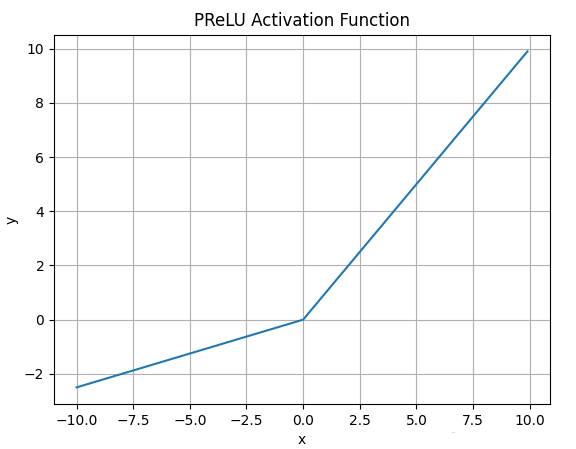
4.5 PReLU
公式:
特点:
- 是训练出来的,不用手动调
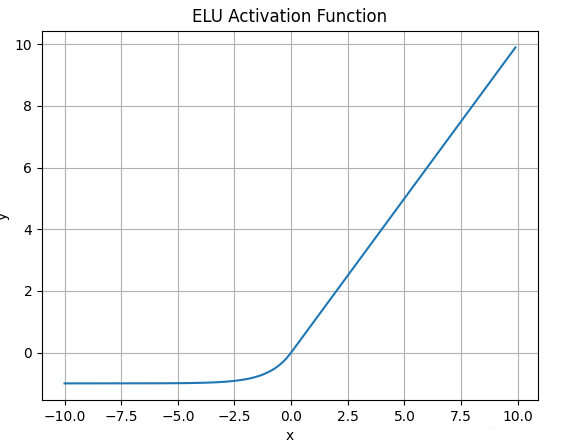
4.6 ELU
公式:
特点:
- 负区间是平滑的指数函数
- 输出均值接近 0,有助收敛 缺点:
- 计算慢(要指数运算)
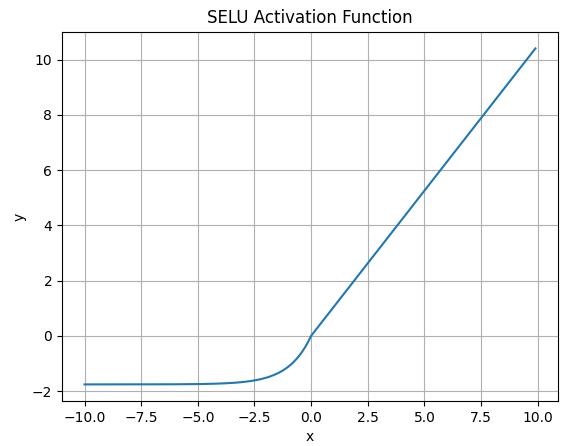
4.7 SELU
公式: 特点:
- 自带“归一化”效果,能让网络自己稳定均值和方差
- 常用于自归一化神经网络(SNN) 缺点:
- 需要特定初始化和网络结构
4.8 Swish
公式:
特点:
- 平滑、非单调,表现优于 ReLU
- Google 提出,ResNet 等模型有用 缺点:
- 计算量比 ReLU 大
4.9 Mish
公式:
特点:
- 比 Swish 更平滑
- 有一定提升泛化能力 缺点:
- 计算复杂
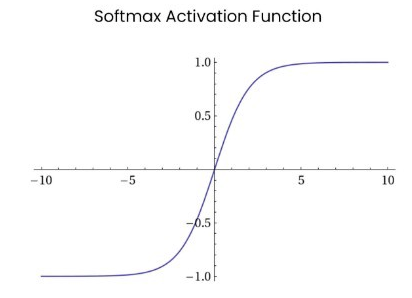
4.10 Softmax
公式:
特点:
- 把输出变成概率分布(总和=1)
- 常用于多分类的输出层