CVPR’24 Tutorial on 3D/4D Generation and Modeling with Generative Priors
3D/4D Generation=Multi-View Image/Video Generation +3D/4D Reconstruction
4D generation
- 当前的 4D 生成研究必须围绕“4D 数据样本有限”这一限制来展开。单视角存在深度/尺度二义性与遮挡,必须引入外部先验或额外观测才能稳定解出 3D。
- 依据生成模型需直接生成的帧比例,将方法分为三类
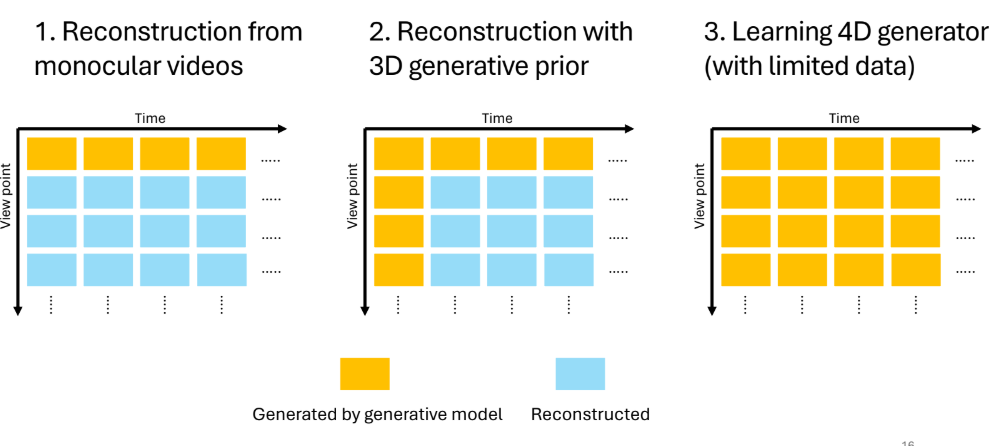
- Reconstruction from monocular videos
- 两大范式
- NRSfM,non-rigid structure from motion
- 典型的 NRSfM 方法以 2D 点对应作为输入,这些对应通过 2D 关键点检测或特征点跟踪获得;NRSfM 算法要为每个点恢复其 3D 位置。
- 由于问题病态,需要引入额外约束以找到有意义解,常见约束包括假设所有点的 3D 位置串联后具有低秩(low-rank)或具有稀疏结构;基于稀疏性或子空间并集(union of subspaces)等假设的思路也被应用到更密集的重建中。
- 在真实世界视频中,可靠的长期跟踪非常困难;例如存在遮挡和出画,这会阻碍你为每个像素得到完整的二维轨迹;还会有模型漂移问题(tracker 丢失目标并错误跟踪到其他物体)。
- Analysis-by-synthesis(单阶段优化)
- 这涉及用可微渲染器把一个 4D 表示渲染成观测信号(如 RGB 图像),并优化该表示以合成输入信号。该单阶段方法通常比两阶段更鲁棒;且因为优化目标是合成与真实图像高度相似的图像,analysis-by-synthesis 方法在视图合成上通常能给出高保真度的结果。
- 要做 analysis-by-synthesis,先表示 4D,以捕捉高保真的 3D 形状与运动。接着,可微渲染器的目标信号并不限于 RGB,还可以包括由单目深度估计器得到的深度图、像素对应(如光流)、二维点跟踪,或用于定位物体部分的语义嵌入。
- NRSfM,non-rigid structure from motion
- 常用的 4D 表示:第一部分是使用某种 3D 表示来建模静态模板形状(通常称为规范化 3D 表示,canonical 3D representation);第二部分是形变表示,用来对模板形状施加变形以合成运动。
- 近年许多论文使用神经辐射场(NeRF)作为规范化 3D 表示,因 NeRF 能产出照片级渲染,并且相比传统表示(如网格)在优化复杂形状时相对容易。最近很多 4D 重建方法转而使用 3D Gaussian Splatting:该技术把对象表示为 3D 点云,每个点用一个高斯代替;与需要射线追踪与点采样的 NeRF 不同,Gaussian Splatting 使用光栅化(rasterization),计算代价更低但仍能达到类似的保真度,因此近期方法倾向用 3D Gaussian Splatting 来变形规范化 3D 表示。
- 谈到如何表示形变,常见做法包括:用神经网络将时空点映射到其在规范化模板上的对应位置(deformation field);另一类是使用形变原语(deformation primitives),如线性混合蒙皮(linear blend skinning,LBS),它把某点的运动表示为若干身体部位或控制点相关刚体运动的组合。这两类表示各有利弊:形变场更通用、理论上能拟合复杂运动,但因过于灵活缺乏归纳偏置,对快速运动的准确重建能力欠佳;而形变原语(如 LBS)为关节物体(人或动物)设计,受限但在重建快速关节运动时表现更好。
- 迄今为止,最先进的 4D 重建通常采用 3D Gaussian Splatting 加上形变表示,如视频所示。该方法比基于 NeRF 的表示(如 Vox)训练更快、渲染显著更快,同时达到相似或更好的渲染保真度。且因为 3D Gaussian Splatting 是类似点云的显式 3D 表示,我们可以独立控制和操作不同高斯点,从而制作有趣的动画(例如让特斯拉 Model X 挥动车门)。
- 可作为监督 / 约束的观测信号(对于 analysis-by-synthesis)
- RGB 重建损失、单目深度图(解歧义关键)、光流 / 长期像素轨迹、分割掩码、连续表面嵌入(人体/动物模板对应):其中最重要的信号之一是由单目深度估计网络预测的深度图。用预训练单目深度估计网络得到的深度图,或许是稳健 4D 重建中最关键的组成。
- Depth:正如前文所述,从单目视频在无任何先验下重建以消除深度与运动间二义性几乎不可能,因此需要用单目深度估计网络提供外部知识,作为直接监督来消解运动中的深度歧义。单目深度估计本身曾是相当具有挑战的问题:数年前的最先进方法在时间一致性上表现欠佳、细节缺失。如论文《consistent depth of moving objects in videos》通过对单个输入视频微调深度网络而能生成时间上更一致的深度估计,但估计的深度图仍缺乏足够细节。近来情况发生变化:社区通过引入先进的自训练技术或利用视频生成模型,显著提升了单目深度估计的准确性。例如新版的 Depth-anything(示例中)可以生成具有细节且时间一致的深度估计。
- Flow / Tracking:光流通常由一个神经网络获得,该网络以两帧图像为输入,迭代估计两帧间每个像素的二维运动。除了估计两帧间的二维像素位移,像 Cracker 这样的最新方法以一段帧序列为输入,能够直接估计长期的二维轨迹。这里有些来自 Cracker 的二维跟踪结果:它能在较长时间内相当准确地追踪移动前景物体上的点。更近的 Spatial Tracker 将 Cracker 扩展为不仅跟踪二维像素位置变化,还输出深度变化,从而能生成三维轨迹。这是非常有前景的方向,可能成为未来最先进 4D 重建方法的关键组成部分。
- 另一类对应关系专门为人类和动物训练,源自密集人体姿态估计(dense human pose estimation)。其思路是为模板形状的每个点学习一个连续的表面嵌入(continuous surface embedding),并训练一个神经网络从二维图像预测嵌入图。用预测到的表面嵌入图,可通过最近邻特征匹配在模板与图像之间找到对应关系。连续表面嵌入已成功应用于人体与动物的重建。
- 最先进的 4D 重建方法
- 第一种方法是 BanMo,它能从视频中重建关节化(articulated)对象,如猫和狗。Banmo 的做法是用 NeRF 作为规范化 3D 表示,并使用线性混合蒙皮(linear blend skinning)作为形变表示,除了 RGB 图像外,还由光流、分割掩码和连续表面嵌入提供监督。
- 较新的方法 MOSA 针对通用动态场景进行了开发,目前是实现新视图合成高质量重建的最佳方法之一。如示例所示,它成功重建了向前滚动的 BB-8 机器人。MOSA 的配方是使用基于高斯的双向查询混合蒙皮(GS dual query blend skinning)作为 4D 表示,并用单目深度图、光流和二维点跟踪进行初始化监督。在 MOSA 的项目页上,他们还展示了对由 Sora 生成视频的令人印象深刻的重建结果。
- 尽管这些结果令人鼓舞,但仍需记住:从单个视频重建 4D 仍非常具有挑战性,当前的 4D 重建方法依旧脆弱,远未达到可投入生产的程度。一项有趣的研究(Dieck 等)发现,许多方法在评估时使用了相机运动较大且场景运动较慢的数据集,这使输入视频更接近于多视图视频(或称为“有效多视图”),而非严格的日常单目视频(通常相机移动较小且场景运动更快)。在这些日常拍摄的视频上测试包括 MOSA 在内的最新方法,会暴露明显伪影,例如快速移动的手指周围出现抖动与伪影。即使是相对简单的物体中心重建(object-centric reconstruction),最先进的方法如 Banmo 仍会产生低保真度的结果,例如狗的头部与尾部未被正确重建,且在身体与尾部交接处可见孔洞。
- 两大范式
- Reconstruction with 3D generative prior
- 这引出第二种方法:使用3D 生成先验(3D generative priors)为 4D 重建与生成提供更强的监督。思路是:给定一个包含物体运动的参考视频,我们可以以参考视频的一帧作为条件,使用预训练的 3D 或多视图生成器为该帧生成 3D 形状,这为我们的帧矩阵提供了一行与一列。挑战在于如何生成其余帧。一个直观想法是把参考视频的其余帧作为条件帧,逐列送入预训练的 3D 或多视图图像生成器来生成每一列,但此法存在问题:每一列互相独立生成,未考虑时间一致性,结果可能随时间不平滑,如该视频所示,从固定视点观看时生成的 4D 内容会出现抖动。
- 如何解决这一问题?最直观的方案是引入时间模型或视频生成模型来生成剩余帧,然而预训练的视频与多视图生成模型并非为共同生成所有帧而设计。在这种情形下有两种潜在方案:一是训练一个联合生成模型直接生成数组中的所有帧,但这会遭遇 4D 训练数据匮乏的问题;另一种不需再训练的方案是使用像 Score Distillation Sampling(SDS)这样的技术来生成这些帧。具体而言,要执行 SDS,我们首先需要一个 4D 表示,并优化它,使其在不同视点和时间渲染出的帧匹配已学到的视频与多视图图像分布。
- 下面是其工作原理:在每个训练步,我们随机采样一行(row),对该行的帧加入高斯噪声并把它们送入预训练的视频扩散模型。该模型会产出去噪估计,我们据此计算并评估 SDS 损失。按行(row-wise)应用分数蒸馏有助于强制时间一致性,防止从不同视点渲染的视频出现抖动。除了用于时间一致性的按行 SDS,我们还对每一列执行 SDS,使用像预训练多视图图像生成模型这样的 3D 生成模型;这可确保在任一时刻,从不同视点渲染的图像与同一参考图像(具有相同运动)一致。最后,关键是要同时对行和列应用 SDS;否则会产生多视角错觉(multi-perspective illusions),这是不可取的。许多 4D 生成方法都遵循分数蒸馏采样(SDS)策略。首个文本到 4D 的方法 Magic3D(文中称为 math 3D/或 aav 3D)使用 SDS 学习带六平面(hex plane)表示的 4D NeRF;将在会中展示的 4DF 在分辨率和细节上对 math3D 作了改进。更近的工作很多都转向高斯点云渲染(gaussian splatting),例如 Dream in 4D 能生成各种运动物体
- 然而还有很大改进空间:如你所见,这些结果通常是以物体为中心、背景简单,且每场景不超过一个动态主体;更关键的是,仔细看生成视频并不十分写实,风格偏卡通且光照不真实。要改进这些方面,尤其实现照片级真实感(photorealism),首先需理解这些“卡通化”风格的来源。问题主要来自用于训练当前 3D 生成模型的数据:最广泛使用的 3D 数据集 ObjectVerse 包含数百万 3D 资产,但其中很多并未被真实纹理化或真实渲染,因此在这些数据上训练的模型不会生成真实风格的 3D 资产。
- 一种有前景的增强照片真实感方法是使用视频生成模型:视频模型可以同时基于物体中心的 3D 数据和大量真实视频联合训练。正如示例所示,像 Snap 的视频模型可以生成“冻结时间”(freeze-time)的视频:背景有环形相机运动、前景对象静止,并且对象在背景环境中具有真实感的放置与光照细节。这促成了我们最近的工作 ForReal ——据我们所知,这是首个能生成近照片级真实 4D 场景并带有细致背景的工作;如后面所示,它也能在一场景中生成多个动态对象。
- 我们如何做到这点?第一步是用文本到视频生成模型生成两段视频:
-
先生成一段参考视频(reference video),其相机轨迹相对静止但包含物体运动;
-
再生成一段“冻结时间”视频(freeze-time video),以第一段参考视频为条件,要求相机做环形运动且几乎没有物体运动。
-
- 有了这些生成的参考视频与冻结时间视频,并借助 SDS,我们可以用高斯点云渲染重建一个规范化的 3D 表示(canonical 3D representation)并捕捉其时序形变(temporal deformations)。优化后的可变形高斯点云(deformable gaussian splatting)允许我们在不同时间渲染冻结时间视频,覆盖接近 180° 的视野范围;它也能渲染来自不同视点的稳定视频。因为使用了视频模型,我们不仅能生成以物体为中心的场景,还能生成带有丰富背景且包含多个动态物体的场景。示例表明该方法能在复杂背景(如鼓组、复杂灯光)下生成非常逼真的外观与运动。
- 不过仍有大量改进空间,例如更高分辨率、更长/更大尺度的运动以及更宽的视野覆盖。我要强调的一个主要限制是速度:基于 SDS 的方法计算量大、生成短 4D 场景也非常慢。例如 4DF 生成一个场景需要超过 10 小时;我们的 ForReal 虽有意减少 SDS 迭代次数,但生成一场景仍约需 1.5 小时。这个限制严重:在高端服务器 GPU 上运行 1 小时以上并不利于大众化使用。我们需要找到推理速度更高、更有前途的方法。
- Learning 4D generator (with limited data)
-
训练一个生成模型,能直接作为多视图视频(multi-view video)一次性生成矩阵中所有帧,而不依赖耗时的运行时优化步骤;随后可以用相对更简单、更高效的方法从这些生成的多视图视频重建 4D 表示。
-
这一切听起来很有希望,但这个多视角视频生成器会是什么样子呢?为理解它,我们先回顾一下扩散模型如何生成视频或多视角图像——从高层看,带噪帧被输入到一系列 Transformer 模块中。
-
在每个 Transformer 模块内,帧先经过一个交叉注意力层(cross-attention),将条件信息应用到潜在特征上,然后经过自注意力层(self-attention),该层对视频帧的补丁间的时空关系建模。
-
交叉注意力与自注意力交替多次应用,直到输出层产生去噪预测。要把该架构扩展到生成多视角视频,可以做一些直接的修改:首先沿时间维度复制交叉注意力和自注意力层,类似并行运行多个多视角图像生成流。
-
然而,如前所述,这依然会产生抖动输出,因为该架构未建模时序关系。一个直接的解决方案是除了自注意力层外再加入跨帧注意力(cross-frame attention)层,这些跨帧注意力有助于对固定视点的单目视频中的时间运动进行推理。
-
这基本概括了近期多视角视频生成工作的最重要组件。尽管网络架构设计相对直白,但由于可用 4D 数据集规模有限,训练这样的模型仍很具挑战性。
-
在一些大规模人体动作捕捉多视图数据集的帮助下,已经能成功训练出能生成特定类别对象(如人类)的模型。例如,最近的工作 Human4DT 训练了一个 Transformer,能够从不同视点在时间上生成可接受的人体结果。
-
但对于无类别限制的文本到 4D(text-to-4D)生成,目前没有太多大规模 4D 数据集可用,这意味着在保持良好泛化能力的前提下去训练该大架构的所有参数是不现实的。
-
因此,几篇近期论文选择冻结主干网络(freeze the backbone),不去学习交叉注意力和自注意力层,而只修改跨帧注意力层以改善不同视点视频流之间的时间一致性。
-
一种无需学习的跨帧注意力设计方法是简单地线性混合图像补丁嵌入的键和值(keys and values)在时间上的表示,这种简单策略被 Stag4D 提出,并显示出在生成 4D 对象方面有一定效果。
-
另一种有前景的方法是从有限的 4D 数据中学习跨帧注意力层。最近几天在 arXiv 上出现的一篇论文 ForDiffusion 使用了来自 ObjectVerse 数据集的大约 900 个带动画的 3D 形状来训练,结果显示出比其他方法更高的质量;若用更多带动画 3D 数据训练,进一步提升也很值得期待。
-